
Дисперсионный анализ биометрия реферат
Обновлено: 03.07.2024
В развитых странах практически любое решение: политическое, финансовое, техническое, научно-исследовательское и даже бытовое решение принимается только после всестороннего анализа данных. Поэтому изучение прикладной статистики и методов анализа данных является неотъемлемым компонентом образования на всех уровнях, а компьютерные пакеты для аналитических исследований и прогнозирования являются настольным рабочим инструментом любого специалиста, так или иначе связанного с информационной сферой.
Известно, что окружающий нас мир характеризуется постоянной изменчивостью, порождающей разнообразие возможностей и свободу выбора. Однако тот, кто серьезно думает о перспективах своей деятельности, обязательно будет накапливать информацию об окружающем мире, пытаясь выделить закономерности из случайностей.
Именно таким мощным и гибким инструментом отсеивания закономерностей от случайностей и является аппарат математической статистики.
Для современной науки характерно применение точных математических методов в самых различных областях. Точность и уровень той или иной области человеческих знаний часто определяется степенью использования соответствующим разделом науки математических методов.
Эволюционная теория Ч. Дарвина, явилась по существу первой эволюционной теорией, которая привнесла в исследования вероятностный дух. Анализ взаимозависимости между такими исходными понятиями эволюционной теории, как изменчивость, наследственность и отбор, оказался бы несостоятельным без того, что сейчас называется вероятностным стилем мышления. Сегодня исследование проблем организации, функционирования, взаимодействия и эволюции живых систем уже немыслимо без привлечения идей и методов теории вероятностей, математической статистики и других разделов математики .
Такие математические методы, которые разработаны с всесторонним учетом принципа единства живой природы и возможности практической их реализации с использование программного обеспечения, является достижением в области постановки и анализа биологических исследований. Однако, опыт показывает, что и в век вычислительной техники лучших успехов достигают те специалисты, которые умеют не только использовать обработанную информацию, но также уяснили сущность применяемых методов. Это предохранит от механического их использования, которое рано или поздно приводит к нелепым или даже абсурдным выводам.
Математическая статистика – раздел математики, посвященный математическим методам систематизации, обработки и использования статистических данных для научных и практических выводов. Математическая статистика исходит из предположения, что наблюдаемая изменчивость наблюдаемого мира имеет два источника. Один из них действие известных причин и факторов. Они порождают изменчивость, закономерно объяснимую. Именно эти изменения и вызывающие ее факторы обычно представляют интерес у исследователя, ищущего, в первую очередь, причинные связи явлений.
Практика накопила большой опыт того, в каких ситуациях приемлемы представления о случайной изменчивости. Для наиболее ходовых из таких ситуаций разработаны математические модели. Наиболее важные и употребительные модели отражены в компьютерных статистических пакетах. Программное воплощение теоретических схем бывает весьма разнообразным, равно как и возможности и производительность реализуемых алгоритмов, а также удобство использования и работы с пакетом.
Кроме основного ядра, в той или иной форме представленного в большинстве пакетов общего назначения, многие из них уделяют предпочтительное внимание отдельным разделам математической статистики и могут содержать менее традиционный или даже новый, оригинальный материал по этим разделам.
Даже в самых конкретных биологических исследованиях основной интерес представляют сведения, относящиеся не к индивидуальному объекту, а к целой группе или некоторому статистическому среднему объекту. Необходимость использования статистических методов в биологических и медицинских исследованиях связана в первую очередь с тем, что свойства биологических объектов обычно значительно варьируют в пределах популяции, а физиологические и другие параметры одной особи испытывают флуктуации во времени.
Традиционно тесные связи между биологической проблематикой и собственно математической статистикой, уже давно позволили выделить рассматриваемую область прикладной статистики в отдельную дисциплину – биометрию.
Биометрия – область научных знаний, охватывающая планирование и анализ результатов количественных биологических экспериментов и наблюдений методами математической статистики.
Современный количественный эксперимент включает в себя самостоятельное математико-статистической исследование, которое начинается со статистического планирования эксперимента, то есть организации его постановки, и завершается статистической обработкой полученных результатов. Поэтому биометрия находит себе все более широкое общебиологическое применение, ибо задачи, которые она решает – планирование экспериментов и анализ их результатов, - составляют основу экспериментальной работы в любой частной области биологии.
Биометрия строится на строгом математическом фундаменте, но этим не ограничивается.
Построение биометрии идет по четырем основным разделам:
Отбор из громадного арсенала математических методов таких, который могут помочь биологам в их текущей работе по наблюдению, преобразованию живой природы;
Модификация отобранных математических методов в соответствии со специфическими особенностями биологических объектов и процессов
Разработка новых биометрических методов, требуемых современным развитием биологии, но еще не имеющихся в арсенале общей математики. Например, расчет показателей наследуемости и повторяемости;
Опираясь на такие особенности ЭВМ, как быстродействие, способность хранить большие объемы информации, предоставление по использованию прикладных программ, существование разнообразных форм выдачи результатов вычислений, расширились возможности биометрии, она стала более доступной. Биометрия основывается теперь не только на таких математических дисциплинах, как теория вероятностей и математическая статистика, но на информатике и программировании на ЭВМ. Это позволяет говорить о современной биометрии как о компьютерной.
Стандартные статистические методы включены в состав популярных электронных таблиц, таких как Excel , Lotus 1-2-3, Quattro Pro , а также в математические пакеты общего назначения, например Mathcad , Maple и др. Однако гораздо большими возможностями обладает специализированное программное обеспечение – статистические программные продукты (СПП).
Международный рынок насчитывает более 1000 пакетов, решающих задачи статистического анализа данных в среде операционных систем Windows , DOS , OS /2.
СПП можно разделить на:
Универсальные пакеты – предлагают широкий диапазон статистических методов. В них отсутствует ориентация на конкретную предметную область. Из зарубежных универсальных пакетов наиболее распространены BAS , SPSS , Systat , Minilab , Statgraphics , STATISTICA .
Специализированные пакеты, как правило, реализуют несколько статистических методов или методы, применяемые в конкретной предметной области. Чаще всего это системы, ориентированные на анализ временных рядов, корреляционно-регресионный, факторный или кластерный анализ. Из российских пакетов известны STADIA , Олимп, Класс-Мастер, КВАЗАР, Статистик-Консультант; американские пакеты – ODA , WinSTAT , Statit и т.д.
Современные СПП реализуют ряд системных функций: ассистирование пользователю при выборе способа обработки, автоматическую организацию процесса обработки данных, обеспечение диалогового режима работы пользователя с пакетом, ведение пользовательских баз данных, автоматическое составление отчета о проделанной пользователем работе, совместимость с другими программами и некоторые другие.
Методориентированные СПП, как правило, имеют следующую структуру:
Блок описательной статистики и разведочного анализа исходных данных: анализ резко выделяющихся значение исследуемого признака, восстановление пропущенных значений, частотная обработка исходных данных (построение гистограмм, полигонов частот, вычисление выборочных средних дисперсий и т.д.), проверка статистических гипотез об однородности исследуемых совокупностей, оценка критериев согласия, визуализация распределения статистических данных и др.;
Блок статистического исследования динамики и зависимостей: дисперсионный и ковариационный анализ, корреляционно-регрессионый анализ, анализ временных рядов и др.;
Блок классификации и снижения размерности: дискриминантный анализ, статистических анализ смесей распределений, кластерный анализ и др.;
Блок методов статистического анализа нечисловых данных и экспертых оценок: анализ таблиц сопряженности, логлинейные модели, ранговые методы и др.;
Блок планирования эксперимента и выборочных исследований;
Блок вспомогательных программ.
Следует отметить, что продвижение западных продуктов в российской аудитории наталкивается на ряд ограничений в связи с неадекватностью культурно-исторической ситуации. Эти пакеты предполагают наличие широкого первоначального статистического образования, доступной литературы и консультационных служб. Поэтому они содержат мало экранных подсказок и требуют внимательного изучения документации на английском языке.
Указанных недостатков в значительной степени лишены известные отечественные статистические пакеты: Эвриста, Статистик-Консультант, STADIA , которые устойчиво представлены на рынке в течение последних лет.
Используемая в данной работе СПП STADIA является универсальной системой, покрывающей в той или иной степени большинство основных разделов прикладной статистики, деловой и научной графики, и по своим интегральным возможностям сравнима с популярными зарубежными пакетами. Набор методов математической статистики, представленный в пакете STADIA составлен исходя из следующих соображений:
в пакет входят все наиболее часто применяемые в России и за рубежом статистические методы;
значительная часть их изучается в вузовских курсах и описана в стандартных учебниках;
пакет не перегружен очень новыми и/или сложными узкоспециализированными методами.
В состав Microsoft Excel входит набор средств анализа данных (называемый пакет анализа), предназначенный для решения сложных статистических и инженерных задач. Microsoft Excel относится к весьма популярным и распространенным электронным таблицам, работающий в среде Windows .
В процессе анализа данных, как правило, присутствуют следующие основные этапы:
Введенные данные обычно отражаются в форме электронной таблицы или матрицы данных, где столбцы представляют различные переменные (например, рост, вес), а строки – измерение значений этих переменных, произведенные в различных условиях, в различное время, у различных объектов и т.п.
Данные в электронной таблице можно просмотреть и скорректировать методами ручного редактирования или же полуавтоматического преобразования к виду, адекватному выбранному методу анализа. Здесь может быть использован широкий набор алгебраических, матричных, структурных преобразований, а также комбинирование этих операций в требуемой последовательности. Нередко также требуются удаление из введенных данных высокоамплитудных выбросов (которые могут быть результатом некорректных измерений) и замена или удаление пропущенных (неизмеренных) значений.
На данные обязательно следует просто посмотреть, чтобы составить общее (в том числе и интуитивное) представление о характере их изменения, специфических особенностях и закономерностях, что очень важно при выборе стратегии и тактики дальнейшего анализа. Для этого можно использовать как исходное числовое представление, так и различные формы графического изображения.
Собственно выбор метода, анализ данных и интерпретация результатов.
Для наглядности производимых выводов полученные результаты желательно представлять в виде адекватных, убедительных и эффектных графиков.
Ранее было показано высокое терапевтическое противоопухолевое действие природного соединения – тиакарпина. На первом этапе изучения нового биологически активного вещества исследовали его общее, физиологическое воздействие на организм. Цель данной работы состояла в изучении и поиске наиболее безвредных доз терапевтического препарата.
В связи с этим были получены результаты эксперимента на животных по влиянию тиакарпина на медико-биологические показатели интактного (здорового) организма. В частности регистрировали такие параметры сердечно-сосудистой системы, как активность ферментов аланинаминотрансферазы (АЛТ) и аспарататаминотрансферазы (АСТ), уровень белка, количество лейкоцитов – клеток иммунного реагирования организма. В печени наблюдали состояние белоксинтетической системы по содержанию в ней общего белка и уровень продуктов тиобарбитуровой кислоты (ТБК) – конечных продуктов перекисного окисления липидов.
Животные (в данном случае беспородные лабораторные мыши) были поделены на группы для выяснения дозо-временного действия препарата. Тиакарпин вводили внутрибрюшинно каждый день в течение всего эксперимента за исключением контрольных животных.

ПРИМЕНЕНИЕ ДИСПЕРСИОННОГО АНАЛИЗА В БИОЛОГИЧЕСКИХ ИССЛЕДОВАНИЯХ
Текст работы размещён без изображений и формул.
Полная версия работы доступна во вкладке "Файлы работы" в формате PDF
На питание рост и развитие рыб, как и других разводимых животных, влияет очень много факторов. В частности это температура воды, рН, соленость воды, обогащенность воды кислородом , полноценность питания и др. Один из основных мероприятий выращивания рыбы это кормление.
Кормление рыб (при прудовом методе разведения) позволяет получать значительно больше продукции, чем при содержании их только на естественной кормовой базе. Однако, для того чтобы оно было эффективным, необходимо знать биологические особенности рыб, потенциальные возможности их роста и пищевые потребности.[1]
Исходя из пищевых потребностей рыб составлены различные комбикорма, кормосмеси , которые полностью поедаются и усваиваются как правило при определенных оптимальных условиях.
Но в природе редко встречаются оптимальные условия. Изменение какого либо фактора сказывается на физиологическом состоянии рыбы, в том числе и на питании.
Если рыба перестает кормиться или отстает от контрольных цифр, необходимо выявить и устранить причину.
Замечательным методом в этом плане, при наличии статистических данных, является дисперсионный анализ, разработанный английским математиком Р. Фишером 1925 году.
Достоинство дисперсионного анализа :
1) С его помощью можно определить величину изменчивости обусловленную воздействием учтенных в опыте факторов.
2) позволяет определить статистическую достоверность доли влияния учтенных в опыте факторов.
3) Его можно применить для обработки совокупности, включающий разнородный материал как для малых, так и для больших выборок.[2]
Таким образом обработка биометрического материала методом дисперсионного анализа позволяет получить самые достоверные данные по любому изучаемому вопросу.
1. Власов В.А. Рыбоводство [Текст]. -СПб: "Лань". 2010. -368 с
2. Меркурьева, Е.К. Генетика с основами биометрии [Текст] учебник/ Е.К.Меркурьева, Г.Н.Шангин-Березовский.- М.: Колос, 1983.- 400 с.
Вспомним, что фиксированными называют такие независимые переменные, которые в эксперименте принимают все возможные значения. Это наиболее распространенный случай, и, как правило, статистические пакеты, используемые для обработки данных, по умолчанию настроены именно на обработку таких данных. Бывает, однако, что исследователь не может в эксперименте объять все возможные значения факторов… Читать ещё >
Двухфакторный дисперсионный анализ ( реферат , курсовая , диплом , контрольная )
Итак, мы увидели, что двухфакторный план позволяет исследовать три эффекта независимых переменных: два основных эффекта факторов и одно взаимодействие между этими двумя независимыми переменными. Кроме того, в двухфакторном межгрупповом плане присутствует эффект статистической (экспериментальной) ошибки, который определяет внутригрупповые различия между испытуемыми одной и той же группы. Эти различия никак не связаны с исследуемыми экспериментальными эффектами.
Таким образом, вся дисперсия, наблюдаемая в экспериментах рассматриваемого типа, может быть разложена на две аддитивные части: 1) дисперсия, определяющая вариативность данных между группами испытуемых, и 2) дисперсия, отражающая вариативность данных внутри самих экспериментальных групп. Дисперсия данных между группами испытуемых, в свою очередь, может быть разложена еще на три аддитивные части: дисперсия, источником которой является каждый из экспериментальных факторов в отдельности, и дисперсия, заданная их взаимодействием. Наглядно эти рассуждения представлены на рис. 5.1.
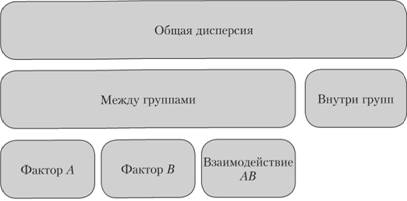
Рис. 5.1. Источники дисперсии в межгрупповом двухфакторном плане.

Тогда, сохраняя принятые в параграфе 5.1 соглашения о средних значениях на каждом уровне независимых переменных и общем среднем, дисперсии (средние квадраты) основных эффектов независимых переменных, очевидно, можно оценить следующим образом:

Средний квадрат взаимодействия факторов А и В оценим по следующей формуле:
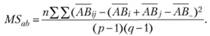
Наконец, эффект статистической ошибки, отражающий внутригрупповые вариации данных, можно оценить так:
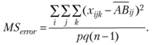
Как обычно, для того, чтобы оценить статистическую надежность экспериментальных эффектов, необходимо правильно построить F-отношение. Однако применительно к факторным планам построение такой статистики оказывается неоднозначным. Дело в том, что правила построения F-отношения разнятся в зависимости от выбранной структурной модели, а она, в свою очередь, среди прочего определяется тем, каким образом трактуются в эксперименте независимые переменные (факторы) — как случайные или как фиксированные.
Структурные модели двухфакторного дисперсионного анализа
Вспомним, что фиксированными называют такие независимые переменные, которые в эксперименте принимают все возможные значения. Это наиболее распространенный случай, и, как правило, статистические пакеты, используемые для обработки данных, по умолчанию настроены именно на обработку таких данных. Бывает, однако, что исследователь не может в эксперименте объять все возможные значения факторов. Например, исследователя могут интересовать процессы идентификации слов, и сами слова рассматриваются как уровни независимой переменной. Понятно, что исследователь в эксперименте всегда ограничен в выборе слов естественного языка вследствие их чрезвычайной многочисленности. В этом случае он случайным образом выбирает из словаря ограниченный набор слов, которые и будут представлять собой случайную выборку уровней соответствующего фактора. Такая независимая переменная будет случайной.
В зависимости от того, какие факторы двухфакторного экспериментального плана будут рассматриваться как фиксированные или случайные, можно выделить три возможные структурные модели (табл. 5.2):
- • полностью фиксированная модель, в которой обе независимые переменные оказываются фиксированными (модель I);
- • смешанная модель, в которой один из экспериментальных факторов оказывается фиксированным, а второй — случайным (модель II);
- • полностью случайная модель, где оба фактора рассматриваются исследователем как случайные (модель III).
Поскольку оба экспериментальных фактора, эффекты которых на зависимую переменную исследуются в эксперименте, равноценны с точки зрения организации и планирования этого эксперимента, в дальнейшим условимся считать, что в смешанной модели фактор А оказывается случайным, а фактор В — фиксированным.
Структурные модели двухфакторного ANOVA для межгруппового плана.
А фиксирован.
А случаен.
В фиксирован.
В случаен.
Будем предполагать, что всякое значение зависимой переменной включает в себя пять аддитивных параметров:
- • популяционную среднюю ?, постоянную для всей генеральной совокупности;
- • эффект фактора А — ?;
- • эффект фактора В — ?;
- • эффект взаимодействия факторов А и В — ??;
- • эффект экспериментальной ошибки — ?.
Иными словами, будем считать, что произвольно выбранный результат испытуемого k в группе ij может быть разложен на следующие составные части:
Как видим, мы снова встречаемся с приложением в экспериментальной работе общих линейных моделей, теперь еще более сложных ("https://referat.bookap.info", 8).
Обозначим прописной латинской буквой число уровней фактора в генеральной совокупности, а строчной — в выборке. Таким образом, Р будет обозначать число уровней фактора А в бесконечном эксперименте, или, что-то же самое, генеральной совокупности. Соответственно, буква Q будет обозначать число уровней фактора В в таком же бесконечном эксперименте, где исследователь может перебрать предельно возможное число уровней этого фактора. Тогда строчные буквы р и q будут обозначать то число уровней факторов А и В, которое исследуется в реальном эксперименте, т. е. выборочные значения уровней независимой переменной.
Теоретически доказано, что средние квадраты, дисперсии, основных экспериментальных эффектов факторов А и В должны описываться следующими соотношениями:
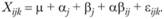
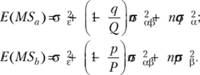
В случае, когда переменные А и В оказываются фиксированными, т. е. когда р = Р и q = Q, эти соотношения, очевидно, должны быть переписаны следующим образом:
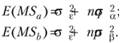
Если же значения факторов А и В, которые будут исследоваться в эксперименте, случайным образом выбираются из бесконечного числа их возможных значений в генеральной совокупности, логично утверждать, что выборочное число уровней независимой оказывается значительно меньшим, чем бесконечно большое число их значений в генеральной совокупности. Тогда можно заключить, что отношения выборочных значений числа уровней независимых переменных к их популяционным значениям пренебрежимо мало отличается от нуля. Таким образом, средние квадраты основных эффектов в случае случайности независимых переменных теоретически должны описываться следующими уравнениями:
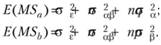
Что касается дисперсии взаимодействия, то ее оцениваемая в эксперименте величина, должна описываться следующим соотношением:
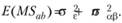

Наконец, ожидаемое значение экспериментальной ошибки будет выражаться так:
Таблица 5.3
Теоретически ожидаемые значения средних квадратов основных эффектов независимых переменных, их взаимодействия и экспериментальной ошибки в двухфакторном межгрупповом эксперименте
фиксированная (модель I).
смешанная (модель II).
случайная (модель II).

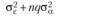
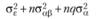
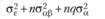

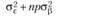
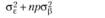
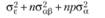
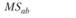


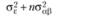
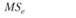



В табл. 5.3 отражены ожидаемые значения оцениваемой дисперсии основных эффектов, их взаимодействия и экспериментальной ошибки для трех возможных структурных моделей двухфакторного дисперсионного анализа применительно к межгрупповому плану. Еще раз отметим, что в данном случае смешанная модель подразумевает случайность фактора А и фиксированность фактора В.
Теперь можно обозначить статистические гипотезы, которые проверяются в двухфакторном эксперименте. Понятно, что они касаются основных эффектов факторов, А и В и их взаимодействия. Если предположить равенство этих эффектов на всех уровнях независимых переменных, то нулевые гипотезы будут выглядеть следующим образом:

Очевидно, что каждая из этих гипотез предполагает нулевое значение эффекта каждого из экспериментальных факторов и их взаимодействия, хотя сами значения . и ?? могут отличаться от нулевых. Иными словами,.
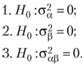
Альтернативные гипотезы, утверждающие неравенство основных эффектов независимых переменных и их взаимодействия на разных уровнях этих переменных, будут выглядеть так:

Тогда для оценки статистической надежности обнаруживаемых в эксперименте эффектов, руководствуясь теоретическими предположениями структурных моделей, отраженными в табл. 5.3, можно сформулировать следующие правила построения F-отношения.
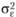
- • Фиксированная модель (модель I). Все эффекты (средние квадраты) оцениваются относительно внутригрупповой дисперсии, представляющей собой ничто иное, как дисперсию экспериментальной ошибки
- • Смешанная модель (модель 11). Эффект случайного фактора оценивается относительно его взаимодействия с фиксированным фактором, а эффект фиксированного фактора и взаимодействие независимых переменных оцениваются относительно внутригрупповой дисперсии.
- • Случайная модель (модель III). Основные эффекты оцениваются относительно их взаимодействия, а само взаимодействие независимых переменных оценивается относительно внутригрупповой дисперсии.
Эти правила можно сформулировать и по-другому: все эффекты в двухфакторном межгрупповом плане необходимо оценивать относительно внутригрупповой дисперсии, за исключением случая, когда оценивается эффект случайной переменной; в этом исключительном случае статистическая надежность определяется относительно взаимодействия случайной переменной с другой независимой переменной.
Следует особо отметить, что оценка эффектов случайных переменных относительно среднего квадрата для взаимодействия имеет смысл только в том случае, когда сам эффект взаимодействия оказывается достаточно выраженным. Если он выражен слабо, необходимо предварительно провести оценку статистической надежности этого эффекта. Если эта оценка дает отрицательный результат, в оценке эффекта случайной переменной необходимо действовать точно так же, как и при оценке эффектов фиксированной переменной.
Вспомним, что фиксированными называют такие независимые переменные, которые в эксперименте принимают все возможные значения. Это наиболее распространенный случай, и, как правило, статистические пакеты, используемые для обработки данных, по умолчанию настроены именно на обработку таких данных. Бывает, однако, что исследователь не может в эксперименте объять все возможные значения факторов… Читать ещё >
Двухфакторный дисперсионный анализ ( реферат , курсовая , диплом , контрольная )
Итак, мы увидели, что двухфакторный план позволяет исследовать три эффекта независимых переменных: два основных эффекта факторов и одно взаимодействие между этими двумя независимыми переменными. Кроме того, в двухфакторном межгрупповом плане присутствует эффект статистической (экспериментальной) ошибки, который определяет внутригрупповые различия между испытуемыми одной и той же группы. Эти различия никак не связаны с исследуемыми экспериментальными эффектами.
Таким образом, вся дисперсия, наблюдаемая в экспериментах рассматриваемого типа, может быть разложена на две аддитивные части: 1) дисперсия, определяющая вариативность данных между группами испытуемых, и 2) дисперсия, отражающая вариативность данных внутри самих экспериментальных групп. Дисперсия данных между группами испытуемых, в свою очередь, может быть разложена еще на три аддитивные части: дисперсия, источником которой является каждый из экспериментальных факторов в отдельности, и дисперсия, заданная их взаимодействием. Наглядно эти рассуждения представлены на рис. 5.1.
Рис. 5.1. Источники дисперсии в межгрупповом двухфакторном плане.
Тогда, сохраняя принятые в параграфе 5.1 соглашения о средних значениях на каждом уровне независимых переменных и общем среднем, дисперсии (средние квадраты) основных эффектов независимых переменных, очевидно, можно оценить следующим образом:
Средний квадрат взаимодействия факторов А и В оценим по следующей формуле:
Наконец, эффект статистической ошибки, отражающий внутригрупповые вариации данных, можно оценить так:
Как обычно, для того, чтобы оценить статистическую надежность экспериментальных эффектов, необходимо правильно построить F-отношение. Однако применительно к факторным планам построение такой статистики оказывается неоднозначным. Дело в том, что правила построения F-отношения разнятся в зависимости от выбранной структурной модели, а она, в свою очередь, среди прочего определяется тем, каким образом трактуются в эксперименте независимые переменные (факторы) — как случайные или как фиксированные.
Структурные модели двухфакторного дисперсионного анализа
Вспомним, что фиксированными называют такие независимые переменные, которые в эксперименте принимают все возможные значения. Это наиболее распространенный случай, и, как правило, статистические пакеты, используемые для обработки данных, по умолчанию настроены именно на обработку таких данных. Бывает, однако, что исследователь не может в эксперименте объять все возможные значения факторов. Например, исследователя могут интересовать процессы идентификации слов, и сами слова рассматриваются как уровни независимой переменной. Понятно, что исследователь в эксперименте всегда ограничен в выборе слов естественного языка вследствие их чрезвычайной многочисленности. В этом случае он случайным образом выбирает из словаря ограниченный набор слов, которые и будут представлять собой случайную выборку уровней соответствующего фактора. Такая независимая переменная будет случайной.
В зависимости от того, какие факторы двухфакторного экспериментального плана будут рассматриваться как фиксированные или случайные, можно выделить три возможные структурные модели (табл. 5.2):
- • полностью фиксированная модель, в которой обе независимые переменные оказываются фиксированными (модель I);
- • смешанная модель, в которой один из экспериментальных факторов оказывается фиксированным, а второй — случайным (модель II);
- • полностью случайная модель, где оба фактора рассматриваются исследователем как случайные (модель III).
Поскольку оба экспериментальных фактора, эффекты которых на зависимую переменную исследуются в эксперименте, равноценны с точки зрения организации и планирования этого эксперимента, в дальнейшим условимся считать, что в смешанной модели фактор А оказывается случайным, а фактор В — фиксированным.
Структурные модели двухфакторного ANOVA для межгруппового плана.
А фиксирован.
А случаен.
В фиксирован.
В случаен.
Будем предполагать, что всякое значение зависимой переменной включает в себя пять аддитивных параметров:
- • популяционную среднюю ?, постоянную для всей генеральной совокупности;
- • эффект фактора А — ?;
- • эффект фактора В — ?;
- • эффект взаимодействия факторов А и В — ??;
- • эффект экспериментальной ошибки — ?.
Иными словами, будем считать, что произвольно выбранный результат испытуемого k в группе ij может быть разложен на следующие составные части:
Как видим, мы снова встречаемся с приложением в экспериментальной работе общих линейных моделей, теперь еще более сложных ("https://referat.bookap.info", 8).
Обозначим прописной латинской буквой число уровней фактора в генеральной совокупности, а строчной — в выборке. Таким образом, Р будет обозначать число уровней фактора А в бесконечном эксперименте, или, что-то же самое, генеральной совокупности. Соответственно, буква Q будет обозначать число уровней фактора В в таком же бесконечном эксперименте, где исследователь может перебрать предельно возможное число уровней этого фактора. Тогда строчные буквы р и q будут обозначать то число уровней факторов А и В, которое исследуется в реальном эксперименте, т. е. выборочные значения уровней независимой переменной.
Теоретически доказано, что средние квадраты, дисперсии, основных экспериментальных эффектов факторов А и В должны описываться следующими соотношениями:
В случае, когда переменные А и В оказываются фиксированными, т. е. когда р = Р и q = Q, эти соотношения, очевидно, должны быть переписаны следующим образом:
Если же значения факторов А и В, которые будут исследоваться в эксперименте, случайным образом выбираются из бесконечного числа их возможных значений в генеральной совокупности, логично утверждать, что выборочное число уровней независимой оказывается значительно меньшим, чем бесконечно большое число их значений в генеральной совокупности. Тогда можно заключить, что отношения выборочных значений числа уровней независимых переменных к их популяционным значениям пренебрежимо мало отличается от нуля. Таким образом, средние квадраты основных эффектов в случае случайности независимых переменных теоретически должны описываться следующими уравнениями:
Что касается дисперсии взаимодействия, то ее оцениваемая в эксперименте величина, должна описываться следующим соотношением:
Наконец, ожидаемое значение экспериментальной ошибки будет выражаться так:
Таблица 5.3
Теоретически ожидаемые значения средних квадратов основных эффектов независимых переменных, их взаимодействия и экспериментальной ошибки в двухфакторном межгрупповом эксперименте
фиксированная (модель I).
смешанная (модель II).
случайная (модель II).
В табл. 5.3 отражены ожидаемые значения оцениваемой дисперсии основных эффектов, их взаимодействия и экспериментальной ошибки для трех возможных структурных моделей двухфакторного дисперсионного анализа применительно к межгрупповому плану. Еще раз отметим, что в данном случае смешанная модель подразумевает случайность фактора А и фиксированность фактора В.
Теперь можно обозначить статистические гипотезы, которые проверяются в двухфакторном эксперименте. Понятно, что они касаются основных эффектов факторов, А и В и их взаимодействия. Если предположить равенство этих эффектов на всех уровнях независимых переменных, то нулевые гипотезы будут выглядеть следующим образом:
Очевидно, что каждая из этих гипотез предполагает нулевое значение эффекта каждого из экспериментальных факторов и их взаимодействия, хотя сами значения . и ?? могут отличаться от нулевых. Иными словами,.
Альтернативные гипотезы, утверждающие неравенство основных эффектов независимых переменных и их взаимодействия на разных уровнях этих переменных, будут выглядеть так:
Тогда для оценки статистической надежности обнаруживаемых в эксперименте эффектов, руководствуясь теоретическими предположениями структурных моделей, отраженными в табл. 5.3, можно сформулировать следующие правила построения F-отношения.
- • Фиксированная модель (модель I). Все эффекты (средние квадраты) оцениваются относительно внутригрупповой дисперсии, представляющей собой ничто иное, как дисперсию экспериментальной ошибки
- • Смешанная модель (модель 11). Эффект случайного фактора оценивается относительно его взаимодействия с фиксированным фактором, а эффект фиксированного фактора и взаимодействие независимых переменных оцениваются относительно внутригрупповой дисперсии.
- • Случайная модель (модель III). Основные эффекты оцениваются относительно их взаимодействия, а само взаимодействие независимых переменных оценивается относительно внутригрупповой дисперсии.
Эти правила можно сформулировать и по-другому: все эффекты в двухфакторном межгрупповом плане необходимо оценивать относительно внутригрупповой дисперсии, за исключением случая, когда оценивается эффект случайной переменной; в этом исключительном случае статистическая надежность определяется относительно взаимодействия случайной переменной с другой независимой переменной.
Следует особо отметить, что оценка эффектов случайных переменных относительно среднего квадрата для взаимодействия имеет смысл только в том случае, когда сам эффект взаимодействия оказывается достаточно выраженным. Если он выражен слабо, необходимо предварительно провести оценку статистической надежности этого эффекта. Если эта оценка дает отрицательный результат, в оценке эффекта случайной переменной необходимо действовать точно так же, как и при оценке эффектов фиксированной переменной.
Читайте также: