
Реляционная база данных это кратко
Обновлено: 02.07.2024
Базы данных всегда являлись краеугольным камнем любого цифрового бизнеса. Поэтому программная индустрия всегда уделяла так много внимания системам управления базами данных.
Концепция реляционных баз данных возникла в 1969 году, когда доктор информатики Эдгар Фрэнк Кодд , исследователь из IBM , написал свою первую статью о проектировании баз данных. С тех пор концепция реляционных баз данных прямо или косвенно используется в любой задаче, решаемой с помощью компьютеров.
Реляционная база данных – это коллекция таблиц, организованная согласно реляционной модели. Каждая ячейка этих таблиц имеет соответствующее формальное описание.
Использование реляционной модели означает, что любой элемент данных может быть идентифицирован при помощи двух уникальных идентификаторов, одним из которых является имя столбца, а другим – содержимое ячеек специального столбца, называемого первичным ключом ( primary key ).
Используя внешние ключи ( foreign keys ), можно установить логическую связь между строками и ячейками разных таблиц.
Организация идеальной реляционной базы данных подразумевает нормализацию данных, то есть исключение повторяющихся или заведомо пустых ячеек при помощи разделения данных на разные таблицы.
Вышеприведённых абзацев вполне хватит, чтобы получить представление о теоретических основах организации реляционных баз данных. Но для настоящего понимания предмета сухой теории недостаточно. Поэтому далее в нашей статье мы попробуем спроектировать базу данных для небольшого приложения.
Данные
Наша база данных будет состоять из двух таблиц: “ Student ” ( студенты ) и “ Class ” ( предметы ), и содержать в себе информацию, соответственно, о студентах и изучаемых ими предметах.
Каждый студент будет обозначен уникальным буквенно-цифровым идентификатором. Остальные данные, относящиеся к студенту – имя и фамилия, операционная система, предмет и преподаватель – могут повторяться. Один преподаватель может учить нескольким предметам.
С учётом этой информации нормализуем данные следующим образом:
1. Таблица студентов будет иметь следующие поля:
- идентификатор студента (Student ID);
- имя студента (Student Name);
- операционная система (Operating System);
2. Таблица предметов будет иметь следующие поля:
- идентификатор предмета (Class ID);
- название предмета (Class Name);
- преподаватель (Instructor).

Теперь заполним обе таблицы данными:


Отношения между объектами
Теперь, используя имеющиеся данные, определим отношения и объекты этих отношений.
Объектами, очевидно, будут являться студенты и предметы. Отношения между ними заключаются в том, что каждый студент изучает один или несколько предметов.
Атрибуты отношений: первичные и внешние ключи
Теперь, когда отношения между объектами ясны, определим атрибуты, которые мы будем использовать для сопоставления объектов друг другу.
Такими атрибутами должны выступать ячейки с уникальным содержимым. В наших таблицах как раз имеется по одному столбцу с уникальными данными.
В таблице студентов у нас есть идентификатор студента, а в таблице предметов – идентификатор предмета. Эти ячейки и называются первичными ключами.
Первичный ключ идентифицирует каждую строку в таблице.

Для установления отношения мы должны сопоставить каждому первичному ключу внешний ключ.
Внешний ключ должен представлять собой первичный ключ другой таблицы. В нашем случае внешний ключ может использоваться для составления особой таблицы – таблицы перекрёстных ссылок. Давайте назовём эту таблицу таблицей зачислений ( enrollment ).
Каждая строка этой таблицы зачислений будет связывать два внешних ключа между собой:
- идентификатор студента (Student ID) – внешний ключ, ссылающийся на идентификатор студента в таблице студентов;
- идентификатор предмета (Class ID) – внешний ключ, ссылающийся на идентификатор предмета в таблице предметов.
Использование таблицы перекрёстных ссылок
Теперь, когда мы определились с ключами и отношениями, мы можем заполнить таблицу перекрёстных ссылок данными об объектах и их зависимостях.

Каждая строка получившейся таблицы однозначно определяется собственным первичным ключом – идентификатором зачисления ( Enrollment ID ).
Кроме первичного ключа, таблица содержит ещё два поля:
- внешний ключ Student ID ссылается на первичный ключ Student ID в таблице студентов;
- внешний ключ Class ID ссылается на первичный ключ Class ID в таблице предметов.
Заключение
Отношения, о которых мы говорили, определяются связями между таблицами базы данных и проявляются как ограничения, накладываемые на допустимый диапазон значений связанных ячеек. Эти ограничения позволяют нормализовать данные, то есть избавиться от ненужных повторений, и связать отдельные таблицы в одно целое.
Как же применить изученные нами примеры на практике?
Я постараюсь вскоре представить вам эту новую статью. Но надеюсь, что и сегодняшний материал был вам полезен, и прошу вас поделиться своими мыслями и замечаниями в комментариях.
Реляционная база данных - база данных, построенная на основе реляционной модели [1] . В реляционной базе каждый объект задается записью (строкой) в таблице. Реляционная база создается и затем управляется с помощью реляционной системы управления базами данных.Фактически реляционная база данных это тело связанной информации, сохраняемой в двухмерных таблицах. Связь между таблицами может находить свое отражение в структуре данных, а может только подразумеваться, то есть присутствовать на неформализованном уровне. Каждая таблица БД представляется как совокупность строк и столбцов, где строки соответствуют экземпляру объекта, конкретному событию или явлению, а столбцы - атрибутам (признакам, характеристикам, параметрам) объекта, события, явления. Реляционные базы данных предоставляют более простой доступ к оперативно составляемым отчетам (обычно через SQL) и обеспечивают повышенную надежность и целостность данных благодаря отсутствию избыточной информации.
Содержание
История
Нечеткость многих терминов, используемых в сфере обработки данных, заставила Кодда отказаться от них и придумать новые или дать более точные определения существующим. Так, он не мог использовать широко распространенный термин "запись", который в различных ситуациях может означать экземпляр записи, либо тип записей, запись в стиле Кобола (которая допускает повторяющиеся группы) или плоскую запись (которая их не допускает), логическую запись или физическую запись, хранимую запись или виртуальную запись и т.д. Вместо этого он использовал термин "кортеж длины n" или просто "кортеж", которому дал точное определение.
Кодд предложил модель, которая позволяет разработчикам разделять свои базы данных на отдельные, но взаимосвязанные таблицы, что увеличивает производительность, но при этом внешнее представление остается тем же, что и у исходной базы данных. С тех пор Кодд считается отцом-основателем отрасли реляционных баз данных. Кодд сформулировал 12 правил для реляционных баз данных, большинство которых касаются целостности и обновления данных, а также доступа к ним.
Правила Кодда
Правило 0: Основное правило (Foundation Rule):
Система, которая рекламируется или позиционируется как реляционная система управления базами данных, должна быть способна управлять базами данных, используя исключительно свои реляционные возможности.
Правило 1: Информационное правило (The Information Rule):
Вся информация в реляционной базе данных на логическом уровне должна быть явно представлена единственным способом: значениями в таблицах.
Правило 2: Гарантированный доступ к данным (Guaranteed Access Rule):
В реляционной базе данных каждое отдельное (атомарное) значение данных должно быть логически доступно с помощью комбинации имени таблицы, значения первичного ключа и имени столбца.
Правило 3: Систематическая поддержка отсутствующих значений (Systematic Treatment of Null Values):
Неизвестные, или отсутствующие значения NULL, отличные от любого известного значения, должны поддерживаться для всех типов данных при выполнении любых операций. Например, для числовых данных неизвестные значения не должны рассматриваться как нули, а для символьных данных — как пустые строки.
Правило 4: Доступ к словарю данных в терминах реляционной модели (Active On-Line Catalog Based on the Relational Model):
Словарь данных должен сохраняться в форме реляционных таблиц, и СУБД должна поддерживать доступ к нему при помощи стандартных языковых средств, тех же самых, которые используются для работы с реляционными таблицами, содержащими пользовательские данные.
Правило 5: Полнота подмножества языка (Comprehensive Data Sublanguage Rule):
Система управления реляционными базами данных должна поддерживать хотя бы один реляционный язык, который (а) имеет линейный синтаксис, (б) может использоваться как интерактивно, так и в прикладных программах, (в) поддерживает операции определения данных, определения представлений, манипулирования данными (интерактивные и программные), ограничители целостности, управления доступом и операции управления транзакциями (begin, commit и rollback).
Правило 6: Возможность изменения представлений (View Updating Rule):
Каждое представление должно поддерживать все операции манипулирования данными, которые поддерживают реляционные таблицы: операции выборки, вставки, изменения и удаления данных.
Правило 7: Наличие высокоуровневых операций управления данными (High-Level Insert, Update, and Delete):
Операции вставки, изменения и удаления данных должны поддерживаться не только по отношению к одной строке реляционной таблицы, но и по отношению к любому множеству строк.
Правило 8: Физическая независимость данных (Physical Data Independence):
Приложения не должны зависеть от используемых способов хранения данных на носителях, от аппаратного обеспечения компьютеров, на которых находится реляционная база данных.
Правило 9: Логическая независимость данных (Logical Data Independence):
Представление данных в приложении не должно зависеть от структуры реляционных таблиц. Если в процессе нормализации одна реляционная таблица разделяется на две, представление должно обеспечить объединение этих данных, чтобы изменение структуры реляционных таблиц не сказывалось на работе приложений.
Правило 10: Независимость контроля целостности (Integrity Independence):
Вся информация, необходимая для поддержания целостности, должна находиться в словаре данных. Язык для работы с данными должен выполнять проверку входных данных и автоматически поддерживать целостность данных.
Правило 11: Независимость от расположения (Distribution Independence):
База данных может быть распределённой, может находиться на нескольких компьютерах, и это не должно оказывать влияния на приложения. Перенос базы данных на другой компьютер не должен оказывать влияния на приложения.
Правило 12: Согласование языковых уровней (The Nonsubversion Rule):
Если используется низкоуровневый язык доступа к данным, он не должен игнорировать правила безопасности и правила целостности, которые поддерживаются языком более высокого уровня.
Сущность реляционной базы данных
Реляционная база данных представляет собой набор таблиц (сущностей). Таблицы состоят из колонок и строк (кортежей). Внутри таблиц могут быть определены ограничения, между таблицами существуют отношения. При помощи SQL можно выполнять запросы, которые возвращают наборы данных, получаемых из одной или нескольких таблиц. В рамках одного запроса данные получаются из нескольких таблиц путем их соединения (JOIN), чаще всего для соединения используются те же колонки, которые определяют отношения между таблицами.
Нормализация — это процесс структурирования модели данных, обеспечивающий связность и отсутствие избыточности в данных. Целью нормализации реляционной базы данных является устранение недостатков структуры базы данных, приводящих к избыточности, которая, в свою очередь, потенциально приводит к различным аномалиям и нарушениям целостности данных.Теоретики реляционных баз данных в процессе развития теории выявили и описали типичные примеры избыточности и способы их устранения. Реляционные хранилища обеспечивают наилучшую смесь простоты, устойчивости, гибкости, производительности, масштабируемости и совместимости. Касаемо масштабируемости, реляционные БД хорошо масштабируются только в том случае, если располагаются на единственном сервере.
Особенностью реляционной базы данных является использование в ней реляционной модели данных и вытекающие из этого последствия:
- Модель данных в реляционных БД определена заранее. Является строго типизированной, содержит ограничения и отношения для обеспечения целостности данных.
- Модель данных основана на естественном представлении содержащихся данных, а не на функциональности приложения.
- Модель данных подвергается нормализации, чтобы избежать дублирования данных. Нормализация порождает отношения между таблицами. Отношения связывают данные разных таблиц.
В реляционной базе данных данные создаются, обновляются, удаляются и запрашиваются с использованием языка структурированных запросов (SQL). SQL-запросы могут извлекать данные как из одиночной таблица, так и из нескольких таблиц.Такие запросы могут включать агрегации и сложные фильтры. Реляционная БД обычно содержит встроенную логику, такую как триггеры, хранимые процедуры и функции.
Реляционная система управления базой данных (РСУБД)
Реляционная система управления базой данных (РСУБД) - СУБД, управляющая реляционными базами данных.
Доступ к реляционным базам данных осуществляется через реляционные системы управления базами данных (РСУБД). Почти все системы баз данных, которые мы используем, являются реляционными, такие как Oracle, SQL Server, MySQL, Sybase, DB2, TeraData и так далее. Причины такого доминирования неочевидны. На протяжении всего существования реляционных БД они постоянно предлагали наилучшую смесь простоты, устойчивости, гибкости, производительности, масштабируемости и совместимости в сфере управлении данными.
Например, простой SELECT запрос может иметь сотни потенциальных путей выполнения, которые оптимизатор оценит непосредственно во время выполнения запроса. Все это скрыто от пользователей, однако внутри РСУБД создает план выполнения, основывающийся на вещах вроде алгоритмов оценки стоимости и наилучшим образом отвечающий запросу. Однако чтобы обеспечить все эти особенности, реляционные хранилища невероятно сложны внутри.

Реляционная база данных – это набор данных с предопределенными связями между ними. Эти данные организованны в виде набора таблиц, состоящих из столбцов и строк. В таблицах хранится информация об объектах, представленных в базе данных. В каждом столбце таблицы хранится определенный тип данных, в каждой ячейке – значение атрибута. Каждая стока таблицы представляет собой набор связанных значений, относящихся к одному объекту или сущности. Каждая строка в таблице может быть помечена уникальным идентификатором, называемым первичным ключом, а строки из нескольких таблиц могут быть связаны с помощью внешних ключей. К этим данным можно получить доступ многими способами, и при этом реорганизовывать таблицы БД не требуется.

Важные аспекты реляционных БД

SQL (Structured Query Language) – основной интерфейс работы с реляционными базами данных. SQL стал стандартом Национального института стандартов США (ANSI) в 1986 году. Стандарт ANSI SQL поддерживается всеми популярными ядрами реляционных БД. Некоторые из ядер также включают расширения стандарта ANSI SQL, поддерживающие специфичный для этих ядер функционал. SQL используется для добавления, обновления и удаления строк данных, извлечения наборов данных для обработки транзакций и аналитических приложений, а также для управления всеми аспектами работы базы данных.
Целостность данных
Транзакция в базе данных – это один или несколько операторов SQL, выполненных в виде последовательности операций, представляющих собой единую логическую задачу. Транзакция представляет собой неделимое действие, то есть она должна быть выполнена как единое целое и либо должна быть записана в базу данных целиком, либо не должен быть записан ни один из ее компонентов. В терминологии реляционных баз данных транзакция завершается либо действием COMMIT, либо ROLLBACK. Каждая транзакция рассматривается как внутренне связный, надежный и независимый от других транзакций элемент.
Соответствие требованиям ACID
Для соблюдения целостности данных все транзакции в БД должны соответствовать требованиям ACID, то есть быть атомарными, единообразными, изолированными и надежными.
Атомарность – это условие, при котором либо транзакция успешно выполняется целиком, либо, если какая-либо из ее частей не выполняется, вся транзакция отменяется. Единообразие – это условие, при котором данные, записываемые в базу данных в рамках транзакции, должны соответствовать всем правилам и ограничениям, включая ограничения целостности, каскады и триггеры. Изолированность необходима для контроля над согласованностью и гарантирует базовую независимость каждой транзакции. Надежность подразумевает, что все внесенные в базу данных изменения на момент успешного завершения транзакции считаются постоянными.
Реляционная база данных — это связанная информация, представленная в виде двумерных таблиц. Представьте себе адресную книгу. Она содержит множество строк, каждая из которых соответствует данному индивидууму. Для каждого из них в ней представлены некоторые независимые данные, например, имя, номер телефона, адрес. Представим такую адресную книгу в виде таблицы, содержащей строки и столбцы. Каждая строка (называемая также записью) соответствует определенному индивидууму, каждый столбец содержит значения соответствующего типа данных: имя, номер телефона и адрес, представленных в каждой строке. Адресная книга может выглядеть таким образом:

То, что мы получили, является основой реляционной базы данных, определенной в начале нашего обсуждения двумерной (строки и столбцы) таблицей информации. Однако, реляционная база данных редко состоит из одной таблицы, которая слишком мала по сравнению с базой данных. При создании нескольких таблиц со связанной информацией можно выполнять более сложные и мощные операции над данными. Мощность базы данных заключается, скорее, в связях, которые вы конструируете между частями информации, чем в самих этих частях.
Установление связи между таблицами
Давайте используем пример адресной книги для того, чтобы обсудить базу данных, которую можно реально использовать в деловой жизни. Предположим, что индивидуумы первой таблицы являются пациентами больницы. Дополнительную информацию о них можно хранить в другой таблице. Столбцы второй таблицы могут быть поименованы таким образом: Patient (Пациент), Doctor (Врач), Insurer (Страховка), Balance (Баланс).

Можно выполнить множество мощных функций при извлечении информации из этих таблиц в соответствии с заданными критериями, особенно, если критерий включает связанные части информации из различных таблиц.
Предположим, Dr.Halben желает получить номера телефонов всех своих Пациентов. Для того чтобы извлечь эту информацию, он должен связать таблицу с номерами телефонов пациентов (адресную книгу) с таблицей, определяющей его пациентов. В данном простом примере он может мысленно проделать эту операцию и узнать телефонные номера своих пациентов Grillet и Brock, в действительности же эти таблицы вполне могут быть больше и намного сложнее.
Программы, обрабатывающие реляционные базы данных, были созданы для работы с большими и сложными наборами тех данных, которые являются наиболее общими в деловой жизни общества. Даже если база данных больницы содержит десятки или тысячи имен (как это, вероятно, и бывает в реальной жизни), единственная команда SQL предоставит доктору Halben необходимую информацию практически мгновенно.
Порядок строк произволен
Для обеспечения максимальной гибкости при работе с данными строки таблицы, по определению, никак не упорядочены. Этот аспект отличает базу данных от адресной книги. Строки в адресной книге обычно упорядочены по алфавиту. Одно из мощных средств, предоставляемых реляционными системами баз данных, состоит в том, что пользователи могут упорядочивать информацию по своему желанию.
Идентификация строк (первичный ключ)
По этой и ряду других причин, необходимо иметь столбец таблицы, который однозначно идентифицирует каждую строку. Обычно этот столбец содержит номер, например, приписанный каждому пациенту. Конечно, можно использовать для идентификации строк имя пациента, но ведь может случиться так, что имеется несколько пациентов с именем Mary Smith. В подобном случае нет простого способа их различить. Именно по этой причине обычно используются номера. Такой уникальный столбец (или их группа), используемый для идентификации каждой строки и обеспечивающий различимость всех строк, называется первичным ключом таблицы (primary key of the table).
Первичный ключ таблицы — жизненно важное понятие структуры базы данных. Он является сердцем системы данных: для того чтобы найти определенную строку в таблице, укажите значение ее первичного ключа. Кроме того, он обеспечивает целостность данных. Если первичный ключ должным образом используется и поддерживается, вы будете твердо уверены в том, что ни одна строка таблицы не является пустой и что каждая из них отлична от остальных.
Столбцы поименованы и пронумерованы
Пример базы данных
Таблицы 1.1, 1. 2, 1.3 образуют реляционную базу данных, которая достаточно мала для того, чтобы можно было понять ее смысл, но и достаточно сложна для того, чтобы иллюстрировать на ее примере важные понятия и практические выводы, связанные с применением SQL.
Можно заметить, что первый столбец в каждой таблице содержит номера, не повторяющиеся от строки к строке в пределах таблицы. Как вы, наверное, догадались, это первичные ключи таблицы. Некоторые из этих номеров появляются также в столбцах других таблиц (в этом нет ничего предосудительного), что указывает на связь между строками, использующими конкретное значение первичного ключа, и той строкой, в которой это значение применяется непосредственно в первичном ключе.
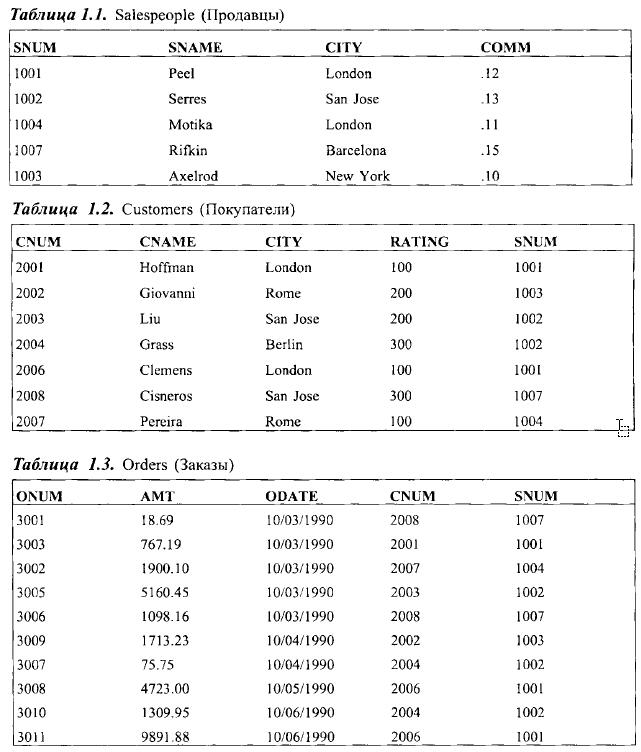
Например, поле snum в таблице Customers определяет, каким продавцом (salespeople) обслуживается конкретный покупатель (customer). Номер поля snum устанавливает связь с таблицей Salespeople, которая дает информацию об этом продавце (salespeople). Очевидно, что продавец, который обслуживает данного покупателя, существует, т.е. значение поля snum в таблице Customers присутствует также и в таблице Salespeople. В этом случае мы говорим, что система находится в состоянии ссылочной целостности (referential integrity).
Сами по себе таблицы предназначены для описания реальных ситуаций в деловой жизни, когда можно использовать SQL для ведения дел, связанных с продавцами, их покупателями и заказами. Давайте зафиксируем состояние этих трех таблиц в какой-либо момент времени и уточним назначение каждого из полей таблицы.
Читайте также: