
Описание объекта для его последующего поиска кратко
Обновлено: 02.07.2024
Свидетельство и скидка на обучение каждому участнику
Зарегистрироваться 15–17 марта 2022 г.
Информатика 11 класс
Тема урока:
Поисковые информационные системы. Организация поиска информации
Цель урока: изучить тему информационные системы и классификацию информационных систем.
Задачи урока:
- помочь учащимся получить представление об информационных системах и рассмотреть основную классификацию информационных систем
- воспитание информационной культуры учащихся, внимательности, дисциплинированности.
- развитие мышления, познавательных интересов, умения конспектировать
Оборудование: доска, компьютер, проектор, экран
Дидактическая оснащенность: компьютерная презентация
I Орг. момент.
Приветствие, проверка присутствующих. Повторение темы из прошлого материала. Объяснение хода урока.
II Теоретическая часть:
Основные принципы работы поисковых систем
Любая поисковая система включает в себя набор следующих компонентов:
База данных (Database) – это хранилище всех страниц, которые были скачаны и обработаны.
Веб-сервер (Web server) – это веб-сервер, отвечающий за правильное взаимодействие пользователя и элементов поисковой системы.
Паук (Spider) – это программа, напоминающая браузер, задача которой заключается в считывании Интернет страницы.
Индексатор (Indexer) – основная задача этой программы это проведение анализа веб-страниц, которые были скачаны пауками.
Система выдачи результатов (Search engine results engine) – используется для извлечения результатов поиска из основной базы данных.
Реализация поисковой системы может и отличаться от приведённой выше блочной структуры, к примеру, связка из паука, краулера и индексатора может быть реализована как один монолитный программный блок. Такой блок будет скачивать Интернет страницу, проводить её анализ, после чего по ссылкам на данной странице будет искать новые Интернет ресурсы.
Database или база данных. Представляет собой хранилище всей информации, которая скачивается и анализируется поисковой системой. В некоторых источниках базу данных могут упоминать как индекс поисковой системы.
Crawler или паук. В ходе работы выделяет все находящиеся на Интернет странице ссылки. Основная его задача заключается в определении ссылки, по которой будет совершён переход и поиск новых документов, которые ещё не были внесены в базу данных поисковой системы. Решение о переходе принимается на основе заранее сформированного списка адресов или на основе ссылок присутствующих на анализируемой странице.
Web server. Чаще всего на сервере существует html-страница с полем ввода, которое используется для поиска ключевых слов или каких-либо терминов. Кроме того, одной из функций веб-сервера является организация выдачи результатов поиска пользователю и представление их в виде html-страницы.
Spider или паук. Программа, основной целью которой является скачивание Интернет страниц. Данная программа работает по тем же принципам что и браузеры, но в отличие от них паук работает напрямую с кодом html, а не отображает информацию в привычном для пользователей виде.
Indexer или индексатор. Осуществляет анализ страницы, разбивая её на отдельные блоки и элементы. В ходе работы выделяются различные элементы, и проводится их детальный анализ. В качестве элементов выступают заголовки, html-теги, структурные особенности, текст, стилевые особенности и многое другое.
Search Engine Results Engine или Система выдачи результатов. Данный блок занимается выбором страниц из базы поисковой системы. Этот компонент поисковой системы является одним из ключевых, он определят, какие страницы подходят под заданные пользователем критерии и в каком порядке их необходимо вывести. Для анализа запроса, поиска соответствующих страниц в базе данных и вывода полученной информации используются специальные базовым алгоритмам ранжирования поисковой системы.
ТЕСТИРОВАНИЕ
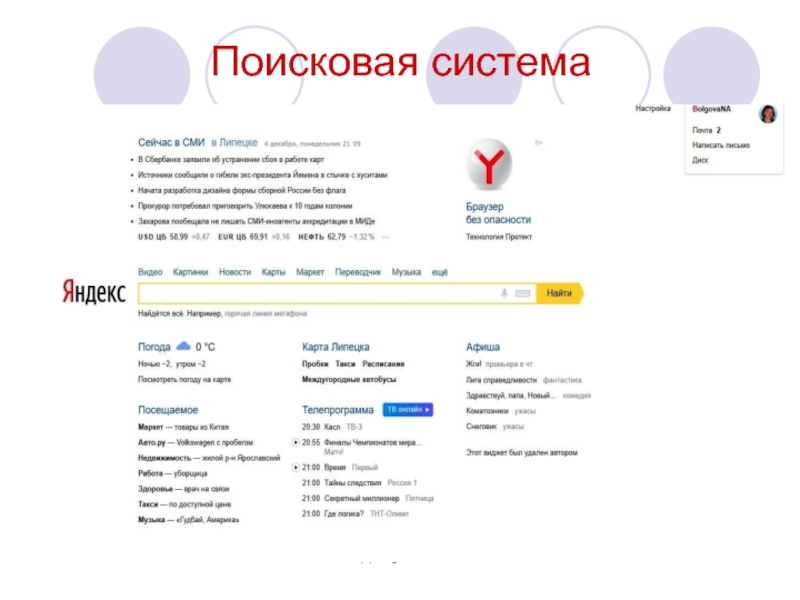
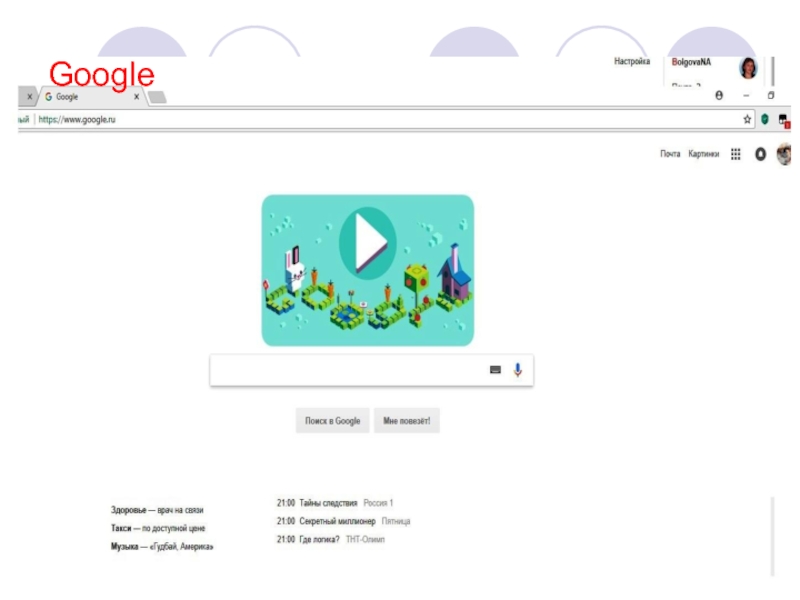
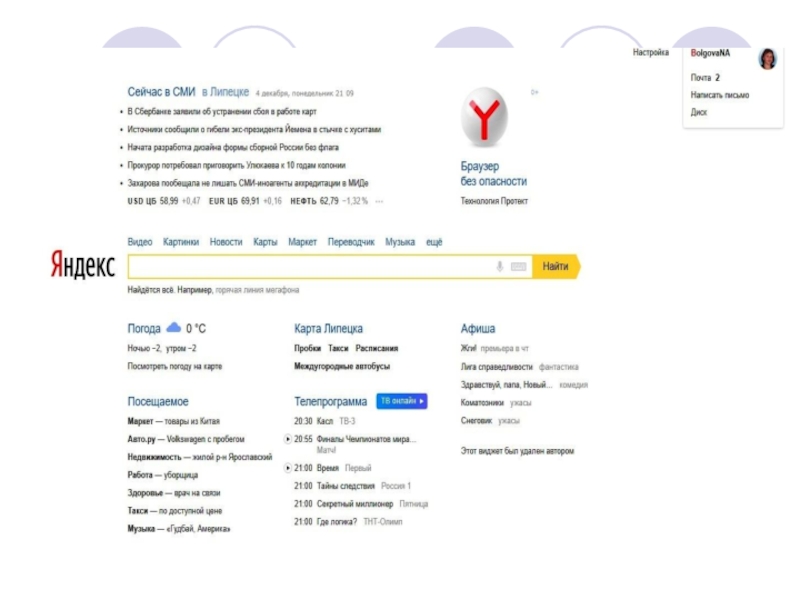
Какой поисковик лучше? – такой вопрос задает себе множество интернет пользователей и ответ на него не так очевиден, как кажется на первый взгляд. Люди спорят, называют свои варианты, но не могут привести никаких убедительных аргументов, а подтверждают сказанное лишь фразой “потому, что лучше и все” и похожими по смыслу высказываниями. Что ж, давайте расставим все точки над “i”, проведя сравнение двух лучших поисковых систем Yandex и Google . Почему именно они? – взгляните на рейтинг использования подобных сервисов в русскоязычном интернете. За Яндексом более 50% от общего числа пользователей, за Google – почти 35%. Остальные сервисы занимают чуть больше 10% от общего оборота и, как вы догадались, особой популярностью не пользуются.
Так какой же поисковик лучше? Яндекс или Гугл?
Рассмотрим со стороны обычного юзера все основные особенности этих поисковых систем: интерфейс, наличие дополнительных сервисов, рекламу и, конечно же, самое важное – качество поиска.
У Google с этим все просто – на главной странице поиска мы не увидим практически ничего, только поисковую строку и ссылки для быстрого перехода на почту и другие гугловские сервисы.
С Яндексом все немного по-другому: главная страница частично отображает информацию с других проектов. Например, меня, как человека, который уже не один год обходится без телевизора, очень радует новостной сервис. Зашел найти информацию в интернете, заметил интересную новость, прочитал. Очень удобно. С другой стороны, для многих все эти дополнения покажутся излишествами, ведь главной задачей поисковых систем является поиск и ничто другое.
Реклама. Большинство интернет пользователей негативно относится к обилию рекламных материалов на сайтах, форумах и прочих ресурсах. Поисковые системы этому не исключение.
Если говорить о Яндексе, то тут всплывает неприятный момент – его создатели помимо контекстных объявлений стали размещать в выдаче еще и баннеры (конечно, не на каждой странице, но все же). Это очень раздражает.
Google не такой жадный и количество блоков контекстной рекламы у него куда меньше, чем у Yandex, плюс нету никаких баннеров. Поэкспериментируйте с различными поисковыми запросами и вы сами убедитесь в этом. В некоторых случаях, Гугл даже не отображает контекст, тогда как Яндекс демонстрирует пользователям стабильно высокое количество рекламы.
Качество поиска. Как я уже говорил ранее, это важнейший критерий при выборе поисковой системы. Оценивается он исходя из того, насколько выводимые результаты соответствуют пользовательским потребностям. А чтобы поисковик как можно чаще попадал “в яблочко”, он должен выводить на странице как можно больше различных вариантов, но в то же время избегать дублей. Например, по запросу “школьник” можно вывести варианты про школьников как учащихся школы, информацию о человеке с фамилией Школьник, фотографии и видео со школьниками, тем самым избавляя пользователя от необходимости еще более конкретизировать свой запрос.
Чтобы сказать точно, что лучше в плане поиска – Яндекс или Гугл, проведем небольшой эксперимент, проанализировав выдачу по трем различным поисковым запросам:
Запрос №1. “Бизнес на сателлитах” .
Запрос №2. “Работа в Нью Йорке” .
Запрос №3. “ДНР” . Если еще учесть, что в поисковой выдаче системы Google куда больше вариантов, чем у Яндекса, можно с уверенностью объявлять по данному пункту ничью.
Дополнительные сервисы.
Гугловская альтернатива тоже весьма хороша. Однако недоступность некоторых сервисов для русской аудитории, а также попытка компании навязать свою социальную сеть Google Plus, рейтинга данной поисковой системе не прибавляют.
Подведем итоги.
Интерфейс – Google подкупает своей аскетичностью и простотой, тогда как Яндекс по максимуму информативен. Поровну . (1:1)
Реклама – Гугл демонстрирует меньше рекламных материалов, чем Яндекс, иногда откровенно злоупотребляющий показом рекламы. Победа за Google . (1:0)
Качество поиска – обе системы в этом плане преуспели , однако у Яндекса более развита коммерческая направленность, а у Гугла информационная. (1:1)
Дополнительные сервисы. Тут победа однозначно за Яндекс . Множество дополнительных сервисов, которые удобно структурированы. У Google их меньше, а проблем с использованием больше.(0:1)
Подсчитав общий результат, мы убедимся, что каждая из поисковых систем набрала одинаковое количество баллов. А это значит, что вопрос так и остался не решенным. Возможно, у вас есть какие-нибудь аргументы в пользу той или иной системы?
Слайды и текст этой презентации

Поисковые информационные системы. Организация поиска информации. Описание объекта для его последующего поиска
Информатика 11 класс (базовый уровень)
Болгова Наталья Анатольевна
МБОУ СОШ с УИОП с.Тербуны

1. В каком году была создана первая глобальная компьютерная сеть?
(1969, ARPANET, США)
2. В каком году появилась Всемирная информационная сеть? Её название?
(1993, World Wide Web, Швейцария)

История World Wide Web
Дата рождения проекта– 6 августа 1991 г.
Основатель- Тим Бернерс-Ли
(европейский центр ядерных
исследований в Женеве),
опубликовал краткое описание
проекта WWW

Аппаратные средства Интернета
Дайте понятие:
1. Компьютерный узел
2. Канал связи
3. Пропускная способность
4. Провайдер
5. IP- адрес
6. Домен
Программные средства Интернета
Дайте понятие:
1. Сервер
2. Клиент
3. Службы Интернета
4. Протокол TCP/ IP
Службы (ресурсы) Интернета
Каково назначение служб Интернета?

Поисковые информационные системы.
Организация поиска информации. Описание объекта для его последующего поиска

Браузер – специальное ПО, обеспечивающее просмотр Web –страниц и перемещение по Всемирной паутине (Интернету)

Компоненты поисковой системы:

Database или база данных
Представляет собой хранилище всей информации, которая скачивается и анализируется поисковой системой.
В некоторых источниках базу данных могут упоминать как индекс поисковой системы.

Crawler или паук
В ходе работы выделяет все находящиеся на Интернет странице ссылки. Основная его задача заключается в определении ссылки, по которой будет совершён переход и поиск новых документов, которые ещё не были внесены в базу данных поисковой системы.
Решение о переходе принимается на основе заранее сформированного списка адресов или на основе ссылок присутствующих на анализируемой странице.

Чаще всего на сервере существует html-страница с полем ввода, которое используется для поиска ключевых слов или каких-либо терминов.
Одной из функций веб-сервера является организация выдачи результатов поиска пользователю и представление их в виде html-страницы.

Spider или паук
Программа, основной целью которой является скачивание Интернет страниц.
Работает по тем же принципам что и браузеры, но в отличие от них паук работает напрямую с кодом html, а не отображает информацию в привычном для пользователей виде.

Indexer или индексатор
Осуществляет анализ страницы, разбивая её на отдельные блоки и элементы.
В ходе работы выделяются различные элементы, и проводится их детальный анализ. В качестве элементов выступают заголовки, html-теги, структурные особенности, текст, стилевые особенности и т.д.

Search Engine Results Engine или Система выдачи результатов.
Данный блок занимается выбором страниц из базы поисковой системы. Данный компонент поисковой системы является одним из ключевых. Он определят, какие страницы подходят под заданные пользователем критерии и в каком порядке их необходимо вывести.
Для анализа запроса, поиска соответствующих страниц в базе данных и вывода полученной информации используются специальные базовым алгоритмам ранжирования поисковой системы.
Яндекс - более 50% от общего числа пользователей
Google – почти 35%
Rambler, Аппорт 2000 - более 10%
Рейтинг использования поисковых систем в русскоязычном Интернете :

Критерии исследования:
Интерфейс
Реклама
Качество поиска
Дополнительные сервисы
Какой поисковик лучше Yandex или Google?

1. Интерфейс :Google - мало информативен и прост, Яндекс - информативен по мах.
2. Реклама: Google - мало рекламных материалов, Яндекс - много
3. Качество поиска: одинаково, но Google более развит в информационном направлении, Яндекс - в коммерческом
4. Дополнительные сервисы:
Яндекс - множество сервисов (+удобно структурированы), Google –меньше (- имеются проблемы с их использованием)

Организация поиска информации. Описание объекта для его последующего поиска
Способы поиска:
1. URL- адрес
2. Гиперссылки
3. Поисковые каталоги
4. Ключевые слова
index.html – главная страница

П 12, вопрос 1,2 (стр 200) внести данные в таблицу
Презентация содержит повторение пройденного материала (компьютерные сети), наглядный материал для объяснения темы (или повторения в форме беседы), а также компьютерный эксперимент по сравнению популярных поисковых систем (возможны 2 вариант: первый - дети работают за ПК, (подключение Интернет), второй – основываясь на личный опыт (без подключения к Интернету).


З-38 Информационно-поисковые системы: Учебно-метод. пособие. — СПб., 2005. — 48 с.
Для студентов и аспирантов, специализирующихся в области прикладной лингвистики, информационных систем и автоматизированных систем обработки текста.
ББК 73:81.1

ã В.П. Захаров, 2005
ã Санкт-Петербургский
государственный
университет, 2005
1. Введение в теорию и практику
информационного поиска
Основные понятия информационного поиска
Информационно-поисковая система (ИПС) — это упорядоченная совокупность документов (массивов документов) и информационных технологий, предназначенных для хранения и поиска информации — текстов (документов) или данных (фактов). Информационно-поиско-выми системами являются любые определенным образом организованные хранилища информации. Причем информационно-поисковые системы могут быть и неавтоматизированными. Главное — это целевая функция: хранение и поиск информации.
В зависимости от объекта хранения и типа запроса различают два вида информационного поиска: документальный и фактографический — и, соответственно, два типа ИПС — документальные и фактографические. Последние также называют информационно-справочными ИПС.
Документальными называются ИПС, в которых реализуется поиск по тематическим запросам в массиве документов или текстов с последующим предоставлением пользователю подмножества этих документов или их копий. Понятие документа может меняться от системы к системе. В общем случае это некий информационный объект, зафиксированный (обычно посредством некоторой знаковой системы) на каком-то материальном носителе (бумага, фото- и кинопленка, магнитная память и т.п.) и предназначенный для передачи в пространстве и времени в системе социальных коммуникаций.
Фактографические ИПС реализуют хранение, поиск и выдачу непосредственно фактических данных (научных, технических, экономических характеристик и свойств объектов, процессов, явлений, адресов, наименований, количественных данных и т.п.).
Главное, сущностное, различие между документальным и фактографическим поиском заключается в подходе к семантике документов. В документальных системах описывается смысл документов в целом с точки зрения их тематического, предметного содержания. В этом случае важно выявить и назвать (перечислить) основные темы и объекты, которым посвящен документ. В фактографических системах описываются объекты, фиксируются их признаки и значения этих признаков. Отсюда различия в языках описания и способах хранения описаний в системе. Соответственно, для каждого вида поиска существуют свои поисковые средства.
Фактографические системы предполагают накопление и поиск в массиве документов со строго регламентированной структурой. Такая структура является или результатом предварительной интеллектуальной обработки документов при вводе информации в систему, или наличием таких документов в готовом виде в конкретных сферах человеческой деятельности, например, учетные формы, бланки, справочники, расписания и т.п. Существуют фактографические ИПС, которые обеспечивают накопление информации и поиск только по одному типу объектов и только по одному типу запросов. Существуют и более развитые фактографические системы, обеспечивающие хранение и поиск данных, разнообразных по содержанию и структуре, но это разнообразие всегда конечно.

В то же время между документальными и фактографическими системами нет непреодолимой разницы. Нередко реальные ИПС представляют собой пример смешанных систем, в которых фактографическая информация используется как дополнительное средство документального поиска, и наоборот. В документальных системах тексты (документы) также могут быть структурированы, разбиты на фрагменты или поля, и обработка и выдача документальной информации может вестись на уровне отдельных полей.
Выделяют еще и третий тип систем, которые называют информационно-логическими. Это системы, отвечающие на запросы, на которые в информационной базе в явном виде ответа нет. Получить ответ помогает экстралингвистическая база знаний и информация, порождаемая алгоритмически из уже имеющейся (документальной или фактографической). Эта новая информация или выдается как ответ на запрос, или дополнительно используется для поиска.
Составные части ИПС называют подсистемами. Разделение на подсистемы необходимо и полезно как в целях разработки, так и для описания технологии функционирования систем. Оно может иметь разную основу. Обычно рассматривают два типа разбиения ИПС на подсистемы: по функциональному принципу (функциональные подсистемы) и по типу средств (обеспечивающие подсистемы).
Информационное обеспечение — это информационные массивы (документы, запросы, метаданные), а также средства и способы их описания, построения и классификации.
Лингвистическое обеспечение — это логико-семантический аппарат, состоящий из информационно-поискового языка, правил применения (методик индексирования), критерия выдачи и других языковых средств.
Программное обеспечение — это алгоритмы и программные средства, реализующие все функции ИПС, выполняемые с помощью компьютера.
Техническое обеспечение — это технические средства (компьютеры, средства телекоммуникаций), обеспечивающие хранение, поиск и передачу информации.
Технологическое обеспечение — это набор и порядок выполнения автоматизированных и неавтоматизированных процессов и процедур обработки информации в ИПС, включая их описание, информационно-технологические схемы и инструктивно-методические материалы.
Кадровое (или штатное) обеспечение — это люди, взаимодействующие с системой и обеспечивающие ее эксплуатацию (обслуживающий персонал).
ИПС также делят на составные части (подсистемы) по функциональному признаку, когда каждая подсистема выполняет определенную функцию в технологическом процессе: ввод документов, индексирование документов, ввод и корректировка запросов, индексирование запросов, поиск, ведение словарей, ведение статистики, обработка результатов поиска, выдача документов и др. Такие части получили название функциональных подсистем.
Важные понятия в информационном поиске — документ и запрос. Документ определяется как средство закрепления любым способом на специальном материале любой информации о фактах, событиях, явлениях объективной действительности и мыслительной деятельности человека. Документы имеют различную форму представления. В автоматизированных документальных ИПС это прежде всего текстовая информация на естественных языках в машиночитаемой форме.
При сопоставлении документов и запросов требуется определить релевантность документа по отношению к запросу и принять решение о выдаче или невыдаче документа на данный запрос. Правила, на основе которых формальноопределяется степень релевантности документа и запроса, т.е. соответствие ПОД и ПОЗ, называются критерием смыслового соответствия (КСС), или критерием выдачи.
Использование булевых операторов обеспечивает логику сравнения документов и запросов, понятную пользователю. Поиск (вычисление истинности для элементов ПП), как правило, проводится по специальным индексным (инвертированным) файлам, построенным на основе словника документального массива, и характеризуется высокой скоростью. Эти простота и понятность логического КСС и явились причиной его широкой распространенности.
Проблема оценки эффективности поиска является комплексной проблемой, включающей как теоретическую, так и практическую сторону. Главные из функциональных (технических) показателей ИПС, базирующихся на релевантности, — это полнота и точность, которые основываются на разделении документов на релевантные и нерелевантные, а также на выданные и невыданные.
Полнотой поиска (П) (англ. Recall — R) называется мера, вычисляемая как отношение количества выданных релевантныхдокументов к общему числу релевантныхдокументов, содержащихся в информационном массиве.
Точность поиска (Т) (англ. Precision — P) — это отношение количества выданных релевантныхдокументов к общему числу документов в выдаче.
В.П. Захаров
ИнформационнО-ПОИСКОВЫЕ
системы
Учебно-методическое пособие
ББК 73:81.1
докт. техн. наук В.Ш. Рубашкин (С.-Петерб. гос. ун-т)
канд. пед. наук О.А. Арбатская (С.-Петерб. гос. ун-т культ. и иск-в)
Печатается по постановлению
Редакционно-издательского совета
С.-Петербургского государственного университета
Захаров В.П.
З-38 Информационно-поисковые системы: Учебно-метод. пособие. — СПб., 2005. — 48 с.
Для студентов и аспирантов, специализирующихся в области прикладной лингвистики, информационных систем и автоматизированных систем обработки текста.
ББК 73:81.1
ã В.П. Захаров, 2005
ã Санкт-Петербургский
государственный
университет, 2005
1. Введение в теорию и практику
информационного поиска
Основные понятия информационного поиска
Информационно-поисковая система (ИПС) — это упорядоченная совокупность документов (массивов документов) и информационных технологий, предназначенных для хранения и поиска информации — текстов (документов) или данных (фактов). Информационно-поиско-выми системами являются любые определенным образом организованные хранилища информации. Причем информационно-поисковые системы могут быть и неавтоматизированными. Главное — это целевая функция: хранение и поиск информации.
В зависимости от объекта хранения и типа запроса различают два вида информационного поиска: документальный и фактографический — и, соответственно, два типа ИПС — документальные и фактографические. Последние также называют информационно-справочными ИПС.
Документальными называются ИПС, в которых реализуется поиск по тематическим запросам в массиве документов или текстов с последующим предоставлением пользователю подмножества этих документов или их копий. Понятие документа может меняться от системы к системе. В общем случае это некий информационный объект, зафиксированный (обычно посредством некоторой знаковой системы) на каком-то материальном носителе (бумага, фото- и кинопленка, магнитная память и т.п.) и предназначенный для передачи в пространстве и времени в системе социальных коммуникаций.
Фактографические ИПС реализуют хранение, поиск и выдачу непосредственно фактических данных (научных, технических, экономических характеристик и свойств объектов, процессов, явлений, адресов, наименований, количественных данных и т.п.).
Главное, сущностное, различие между документальным и фактографическим поиском заключается в подходе к семантике документов. В документальных системах описывается смысл документов в целом с точки зрения их тематического, предметного содержания. В этом случае важно выявить и назвать (перечислить) основные темы и объекты, которым посвящен документ. В фактографических системах описываются объекты, фиксируются их признаки и значения этих признаков. Отсюда различия в языках описания и способах хранения описаний в системе. Соответственно, для каждого вида поиска существуют свои поисковые средства.
Фактографические системы предполагают накопление и поиск в массиве документов со строго регламентированной структурой. Такая структура является или результатом предварительной интеллектуальной обработки документов при вводе информации в систему, или наличием таких документов в готовом виде в конкретных сферах человеческой деятельности, например, учетные формы, бланки, справочники, расписания и т.п. Существуют фактографические ИПС, которые обеспечивают накопление информации и поиск только по одному типу объектов и только по одному типу запросов. Существуют и более развитые фактографические системы, обеспечивающие хранение и поиск данных, разнообразных по содержанию и структуре, но это разнообразие всегда конечно.
В то же время между документальными и фактографическими системами нет непреодолимой разницы. Нередко реальные ИПС представляют собой пример смешанных систем, в которых фактографическая информация используется как дополнительное средство документального поиска, и наоборот. В документальных системах тексты (документы) также могут быть структурированы, разбиты на фрагменты или поля, и обработка и выдача документальной информации может вестись на уровне отдельных полей.
Выделяют еще и третий тип систем, которые называют информационно-логическими. Это системы, отвечающие на запросы, на которые в информационной базе в явном виде ответа нет. Получить ответ помогает экстралингвистическая база знаний и информация, порождаемая алгоритмически из уже имеющейся (документальной или фактографической). Эта новая информация или выдается как ответ на запрос, или дополнительно используется для поиска.
Составные части ИПС называют подсистемами. Разделение на подсистемы необходимо и полезно как в целях разработки, так и для описания технологии функционирования систем. Оно может иметь разную основу. Обычно рассматривают два типа разбиения ИПС на подсистемы: по функциональному принципу (функциональные подсистемы) и по типу средств (обеспечивающие подсистемы).
Информационное обеспечение — это информационные массивы (документы, запросы, метаданные), а также средства и способы их описания, построения и классификации.
Лингвистическое обеспечение — это логико-семантический аппарат, состоящий из информационно-поискового языка, правил применения (методик индексирования), критерия выдачи и других языковых средств.
Программное обеспечение — это алгоритмы и программные средства, реализующие все функции ИПС, выполняемые с помощью компьютера.
Техническое обеспечение — это технические средства (компьютеры, средства телекоммуникаций), обеспечивающие хранение, поиск и передачу информации.
Технологическое обеспечение — это набор и порядок выполнения автоматизированных и неавтоматизированных процессов и процедур обработки информации в ИПС, включая их описание, информационно-технологические схемы и инструктивно-методические материалы.
Кадровое (или штатное) обеспечение — это люди, взаимодействующие с системой и обеспечивающие ее эксплуатацию (обслуживающий персонал).
ИПС также делят на составные части (подсистемы) по функциональному признаку, когда каждая подсистема выполняет определенную функцию в технологическом процессе: ввод документов, индексирование документов, ввод и корректировка запросов, индексирование запросов, поиск, ведение словарей, ведение статистики, обработка результатов поиска, выдача документов и др. Такие части получили название функциональных подсистем.
Важные понятия в информационном поиске — документ и запрос. Документ определяется как средство закрепления любым способом на специальном материале любой информации о фактах, событиях, явлениях объективной действительности и мыслительной деятельности человека. Документы имеют различную форму представления. В автоматизированных документальных ИПС это прежде всего текстовая информация на естественных языках в машиночитаемой форме.
При сопоставлении документов и запросов требуется определить релевантность документа по отношению к запросу и принять решение о выдаче или невыдаче документа на данный запрос. Правила, на основе которых формальноопределяется степень релевантности документа и запроса, т.е. соответствие ПОД и ПОЗ, называются критерием смыслового соответствия (КСС), или критерием выдачи.
Использование булевых операторов обеспечивает логику сравнения документов и запросов, понятную пользователю. Поиск (вычисление истинности для элементов ПП), как правило, проводится по специальным индексным (инвертированным) файлам, построенным на основе словника документального массива, и характеризуется высокой скоростью. Эти простота и понятность логического КСС и явились причиной его широкой распространенности.
Проблема оценки эффективности поиска является комплексной проблемой, включающей как теоретическую, так и практическую сторону. Главные из функциональных (технических) показателей ИПС, базирующихся на релевантности, — это полнота и точность, которые основываются на разделении документов на релевантные и нерелевантные, а также на выданные и невыданные.
Полнотой поиска (П) (англ. Recall — R) называется мера, вычисляемая как отношение количества выданных релевантныхдокументов к общему числу релевантныхдокументов, содержащихся в информационном массиве.
Точность поиска (Т) (англ. Precision — P) — это отношение количества выданных релевантныхдокументов к общему числу документов в выдаче.
Читайте также: