
Кратко охарактеризуйте модель построения леса единый лес каждый регион отдельное дерево
Обновлено: 04.07.2024
Правильные ответы выделены зелёным цветом.
Все ответы: Курс является обобщением практики внедрения службы Active Directory. Даны необходимые термины, приведена архитектура Active Directory, а также необходимые модели и стратегии. Описаны процессы планирования, проектирования, развертывания и тестирования Active Directory, освещен вопрос миграции данных. В заключение отображены нюансы управления мониторингом Active Directory, а также устранение возможных проблем, как при миграции данных, так и при функционировании службы.
(1) контроллеры домена должны реплицировать информацию друг у друга, если они расположены в разных офисах компании
(2) контроллеры домена должны реплицировать информацию друг у друга, если количество контроллеров домена превышает число сайтов для домена
(3) независимо от того, сколько контроллеров домена имеет компания и где они расположены, контроллеры домена должны реплицировать информацию друг у друга
Какие этапы должны быть включены в план миграции существующей доменной структуры компании на доменную структуру Active Directory?
(4) определение момента переключения для каждого домена из основного режима в смешанный режим Windows
(5) тестирование имеющихся критичных приложений в окружении Active Directory в смешанном режиме работы контроллеров доменов
(1) гарантия того, что изменения в сети и рабочей среде не будут отрицательно влиять на работу Active Directory
(2) ежедневный профилактический мониторинг состояния службы каталога необходим для поддержания надежности Active Directory
(3) мониторинг службы каталога является комбинацией задач, имеющих общую цель - измерение текущей характеристики некоторого ключевого индикатора по сравнению с текущим состоянием другого индикатора
(4) мониторинг идентифицирует потенциальные проблемы прежде, чем они проявятся и закончатся длительными периодами простоя службы
(5) мониторинг дает возможность поддерживать соглашение об уровне сервиса (Service-Level Agreement, SLA) с пользователем сети
(6) необходимо отслеживать изменения инфраструктуры - увеличение размера базы данных Active Directory, функционирование серверов глобального каталога (GC) в интерактивном режиме, время репликации между географически разнесенными контроллерами доменов
(2) первые шаги в восстановлении системы в случае отказа выполняются непосредственно после того, как случится сам отказ
(3) первые шаги в восстановлении системы после отказа выполняются намного раньше, чем случится сам отказ
(1) область действия Active Directory может включать отдельные сетевые объекты (принтеры, файлы, имена пользователей)
(2) область действия Active Directory может включать серверы и домены в отдельной глобальной сети, а также охватывать несколько объединенных сетей
(3) область действия Active Directory относится только к управлению отдельным компьютером, но не к компьютерной сети или группе сетей
(2) модель данных Active Directory можно представить в виде многоуровневой архитектуры, в которой уровни являются процессами, предоставляющими клиентским приложениям доступ к службе каталога
(4) в каталоге хранятся объекты, которые представляют собой самые различные единицы хранения, описываемые с помощью атрибутов
(3) данная модель позволит гибко контролировать членство в группах Enterprise Admins, Schema Admins и исключить присутствие в них по умолчанию всех администраторов центрального офиса
(4) административные группы Enterprise Admins, Schema Admins, дающие их членам административные полномочия в лесу, вынесены в отдельный корневой домен
(5) в корневом домене наряду с группами Enterprise Admins, Schema Admins существуют остальные пользовательские учетные записи центрального офиса
(6) любой пользователь, попадающий в группу Admins, становится Enterprise Admins, так как группа Admins входит в группы Enterprise Admins и Schema Admins
(5) в большинстве случаев служба DNS в Active Directory не должна взаимодействовать с имеющейся инфраструктурой DNS
(3) расписание и маршрут репликации каталога домена могут быть сконфигурированы для внутри- и межсайтовой репликации по отдельности
(2) X.500 - спецификация Internet Standards Organization (ISO), определяющая, как должны быть структурированы глобальные каталоги
(3) Протокол DAP описывает применение Х.500 для обеспечения взаимодействия между клиентами и серверами каталогов
(4) со стандартом Х.500 совместима, в том числе, служба каталогов для сетей Novell NetWare - Novell Directory Services (NDS)
(3) когда создается, удаляется или переносится объект либо изменяются его атрибуты на любом контроллере домена, эти изменения реплицируются на остальные контроллеры домена
(5) предупреждение не уведомляет администрацию сети (или оператора мониторинга) о текущем состоянии системы
(6) предупреждение может инициировать автоматические действия, направленные на решение проблемы или предотвращение дальнейшего ухудшения состояния службы
Укажите возможные решения проблемы с Active Directory, в результате которой в Active Directory невозможно добавить или удалить домен
(1) объект - это непустой, именованный набор атрибутов, обозначающий нечто конкретное, например, пользователя, принтер или приложение
(2) контейнер не обозначает ничего конкретного: он может содержать группу объектов или другие контейнеры
(3) контейнер аналогичен объекту в том смысле, что он также имеет атрибуты и не принадлежит пространству имен
(1) логическая структура является моделью службы каталога, которая определяет каждого участника безопасности на предприятии, а также организацию этих участников
(2) сетевые ресурсы организованы в логическую структуру, что позволяет находить определенный ресурс только по его конкретному физическому расположению
(3) основные компоненты логической структуры - объекты, домены, доменные деревья, леса, организационные единицы
Кратко охарактеризуйте модель построения леса "Единый лес, административный корневой домен, каждый регион - домен"
(5) любой пользователь, попадающий в группу Admins, становится Enterprise Admins, так как группа Admins входит в группы Enterprise Admins и Schema Admins
(6) административные группы Enterprise Admins и Schema Admins, дающие их членам административные полномочия в лесу, вынесены в отдельный корневой домен
(7) существует отдельное дерево с корневым доменом, хранящим группы Enterprise Admins и Schema Admins
(8) данная модель позволит гибко контролировать членство в группах Enterprise Admins и Schema Admins и исключить присутствие в них по умолчанию всех администраторов центрального офиса
(3) учетные записи компьютеров позволяют добавлять серверы приложений как рядовые серверы (member servers) в доверяемые сайты
(4) учетные записи компьютеров позволяют запрашивать аутентификацию пользователей или служб, которые обращаются к этим серверам ресурсов
(1) обеспечивать защиту информации от вмешательства посторонних лиц в рамках, установленных администратором системы
(3) проводить репликацию (тиражирование) каталога, делая его доступным для большего числа пользователей и более защищенным от потери данных
(4) разделять каталог на несколько частей, обеспечивая возможность хранения очень большого числа объектов
(1) в пределах сайта автоматически создается топология репликации с использованием кольцевой структуры
(2) кольцевая структура обеспечивает существование минимум двух путей репликации от одного контроллера домена до другого
(3) если один контроллер домена временно становится недоступен, то репликация на остальные контроллеры домена прекращается
За какими элементами (областями работы) рекомендуется планировать наблюдение при проектировании мониторинга Active Directory?
(3) после того как журнал Edbtemp.log переименовался в следующий предшествующий журнал, журнал Edb.log переименовывается в журнал Edbtemp.log
(1) физическая структура является моделью службы каталога, которая определяет каждого участника безопасности на предприятии, а также организацию этих участников
(2) физическое проявление службы Active Directory состоит в наличии отдельного файла данных, расположенного на каждом контроллере домена в домене
(3) основные компоненты физической структуры - объекты, домены, доменные деревья, леса, организационные единицы
(1) самое главное решение, которое необходимо принять на раннем этапе разработки Active Directory, - сколько лесов потребуется
(2) использование единственного леса для большой корпорации не требует высокой степени доверия между разнообразными деловыми подразделениями
(3) необходимо привлечение бизнес-заказчиков, которые являются основными потребителями услуг, обеспечиваемых ИТ-инфраструктурой
(4) количество развертываемых лесов зависит от легкости совместного использования информации в пределах каждого домена леса
(5) количество развертываемых лесов зависит от того, что является наиболее важным для компании: легкость совместного использования информации в пределах всех доменов леса или поддержка полностью автономного и изолированного управления частями структуры каталога
Кратко охарактеризуйте модель построения леса "Единый лес, каждый регион - дочерний домен центрального домена"
(3) в корневом домене наряду с группами Enterprise Admins и Schema Admins существуют остальные пользовательские учетные записи центрального офиса
(4) любой пользователь, попадающий в группу Admins, становится Enterprise Admins, так как группа Admins входит в группы Enterprise Admins и Schema Admins
(5) административные группы Enterprise Admins, Schema Admins, дающие их членам административные полномочия в лесу, вынесены в отдельный корневой домен
(6) существует отдельное дерево с корневым доменом, хранящим группы Enterprise Admins и Schema Admins
(1) обеспечение Active Directory информацией, которая необходима клиентам для поиска контроллеров домена в сети
(2) список всех офисов компании, в которых компьютеры связаны через высокоскоростные сетевые соединения
(4) количество пользователей, компьютеров, серверов и локальных подсетей IP для каждого офиса компании
Перечислите высказывания, справедливые для функции службы каталогов Active Directory по централизации
(2) включение информации обо всех сетевых ресурсах в централизованный каталог создает множество точек управления
(3) централизация упрощает администрирование ресурсов и позволяет эффективнее делегировать административные задачи
(4) в сети появляется единая точка входа для пользователей (или их компьютеров/приложений), когда возникает необходимость в поиске ресурсов
(1) информация о схеме - определяет, какие объекты разрешается создавать в каталоге и какие у них могут быть атрибуты
(1) нельзя установить Active Directory, не имея на компьютере службы DNS, потому что Active Directory использует DNS в качестве службы поиска
(2) для конфигурирования DNS-сервера автоматически надо воспользоваться резервными файлами Active Directory
Укажите соответствие обновления домена критерию удовлетворенности имеющейся моделью существующего домена
(1) обновление домена применяется, если нет никаких существенных изменений, которые хотелось бы сделать в доменной модели
(3) тестировать изменения конфигурации или параметры настройки системы посредством мониторинга результатов
(3) в IP-конфигурации контроллеров доменов должны быть правильно заданы основные и альтернативные DNS-серверы
(1) домен - это единая область, в пределах которой обеспечивается безопасность данных в компьютерной сети под управлением ОС Windows
(2) границы одного домена точно совпадают с одним физическим устройством, например, с рабочей станцией
(3) домены являются составляющими компонентами для службы Active Directory, которые имеют собственные правила защиты информации
(3) каждый контроллер домена хранит полную копию всей информации Active Directory, относящейся к его домену
(6) контроллеры домена управляют взаимодействием пользователей и домена, например, находят объекты Active Directory и распознают попытки входа в сеть
Охарактеризуйте доверие к лесу (forest trust), применяемое при управлении отношениями между двумя лесами
Перечислите основные преимущества использования интегрированных зон (integrated zones) Active Directory
(2) зонная информация хранится в базе данных Active Directory, что обеспечивает дополнительную защиту
(1) DNS должна быть развернута в каждом офисе организации, за исключением, быть может, только очень маленьких офисов с несколькими пользователями
(3) если сконфигурировать DNS-сервер как сервер, предназначенный только для кэширования, то он будет оптимизировать поиски клиента, но не создаст трафика зонной передачи
(1) хранить информацию об объектах сети и предоставлять эту информацию пользователям и системным администраторам
(3) для обновления домена требуется меньше времени при выполнении всего перехода, чем для реструктуризации домена
(4) для обновления домена требуется больше времени при выполнении всего перехода, чем для реструктуризации домена
Укажите возможные причины, в связи с которыми при репликации появляются отказы между контроллерами домена
(2) сайты, включающие клиентов и контроллеры домена, не имеют связей с контроллерами доменов другого сайта сети, что вызывает сбои в обмене информацией каталога между сайтами
(3) хотя все сайты соединены связями, существующая структура межсайтовой репликации недостаточно полна
(5) информация каталога, изменившаяся на контроллерах домена в одном сайте, своевременно не обновилась на контроллерах домена в других сайтах, поскольку заданная в расписании частота межсайтовой репликации слишком низка
(6) клиенты пытаются запросить аутентификацию, информацию и службы у контроллера домена по подключению с низкой пропускной способностью
(3) лес существует в виде совокупности объектов с перекрестными ссылками и доверительных отношений на основе протокола Kerberos, установленных для входящих в лес деревьев
(4) лес, в отличие от дерева, является строго поименованной сущностью, состоящей из нескольких деревьев
(1) сайт - это группа контроллеров доменов, которые находятся в единой или нескольких IP-подсетях и связаны скоростными и надежными сетевыми соединениями
(4) концепция сайтов основывается на том, что ее основу составляет IP-сеть, для которой надо обеспечить наилучшие условия подключений вне зависимости от используемых приложений
(5) контроллеры доменов внутри сайта могут свободно реплицировать изменения в базу данных Active Directory всякий раз, когда происходят такие изменения
(6) контроллеры доменов в разных сайтах не сжимают трафик репликации, потому что передают его по определенному расписанию
(4) единственный способ иметь различную политику паролей, политику блокировки учетных записей и политику билетов Kerberos
(2) необходимо создание двух учетных записей для каждого пользователя: одну в создаваемом домене, другую - в существующем
(3) доступ учетных записей пользователей из существующего домена к ресурсам нового домена автоматически разрешен на уровне доверительных отношений между доменами
(7) пользователи, находясь внутри корпоративной сети, смогут получить доступ к ресурсам всей сети (регионы и центральный офис) согласно правам доступа
(8) рекомендуется создать стратегию именования, определяющую единообразный подход к формированию имен
(1) административные полномочия распределены между несколькими филиалами, расположенными в разных местах
(1) контроллеры домена следует располагать в большинстве офисов компании, где есть значительное количество пользователей
(3) трафик входа клиентов в систему гарантировано не пересекается с WAN-подключениями к различным офисам
(5) если трафик репликации на контроллер домена, расположенный в данном месте, выше, чем трафик входа клиентов в систему
(1) Active Directory является единственной централизованной службой каталога, которая может быть реализована в пределах предприятия
(2) администраторы должны соединяться с несколькими каталогами, чтобы выполнять управление учетными записями
(3) централизованный каталог может также применяться другими приложениями, и это упрощает полное сетевое администрирование, так как используется единая служба каталога для всех приложений
(4) после успешной идентификации пользователям будет предоставлен доступ ко всем сетевым ресурсам, для которых им было дано разрешение, без необходимости регистрироваться снова на различных серверах или доменах
(5) служба Active Directory не использует подсистему безопасности Windows при обеспечении защиты общедоступных сетевых ресурсов
(6) отдельный домен Active Directory может поддерживать не более одной тысячи объектов, так что модель отдельного домена подходит только для небольших организаций
Какие существуют типы обновлений информации в Active Directory, касающейся определенного контроллера домена?

(4) повышенная защищенность - аутентификация по протоколу Kerberos, группы Enterprise Admins и Schema Admins находятся в отдельном корневом домене, Schema master находится в отдельном домене
(5) сокращение количества компьютеров - контроллеров домена из-за отсутствия корневого "пустого" домена
Номер 3
Ответ:
(2) для наличия права создания новых деревьев/доменов администратор должен присутствовать в группе Enterprise Admins
(3) необходимы дополнительные усилия по контролю членства в группах Enterprise Admins и Schema Admins (не допускать в них группу Admins)
(4) если в организации уже развернута структура Active Directory, то контроллеры домена в этой организации необходимо переустановить
Упражнение 3: Номер 1
Ответ:
(3) в корневом домене наряду с группами Enterprise Admins и Schema Admins существуют остальные пользовательские учетные записи центрального офиса
(4) любой пользователь, попадающий в группу Admins, становится Enterprise Admins, так как группа Admins входит в группы Enterprise Admins и Schema Admins
(5) административные группы Enterprise Admins, Schema Admins, дающие их членам административные полномочия в лесу, вынесены в отдельный корневой домен
(6) существует отдельное дерево с корневым доменом, хранящим группы Enterprise Admins и Schema Admins
Номер 2
Ответ:
(1) пользователи могут просматривать ресурсы центрального офиса и регионов при соответствующих правах доступа к объектам Active Directory
(5) сокращение количества компьютеров - контроллеров домена из-за отсутствия корневого "пустого" домена
Номер 3
Ответ:
(2) для наличия права создания новых деревьев/доменов, администратор должен присутствовать в группе Enterprise Admins
(4) необходимы дополнительные усилия по контролю членства в группах Enterprise Admins и Schema Admins (не допускать в них группу Admins)
(5) если в организации уже развернута структура Active Directory, то контроллеры домена в этой организации необходимо переустановить
Упражнение 4: Номер 1
Ответ:
Номер 2
Ответ:
(2) создание автономного подразделения, в таком случае для отдельного леса схема может поддерживаться и изменяться, не оказывая влияния на другие леса
(3) создание изолированного подразделения, потому что в изолированном лесу администратор вне леса не сможет повлиять на управление им
Номер 3
Ответ:
(1) при наличии нескольких лесов существует несколько глобальных каталогов, и пользователям приходится указывать, в каком лесу вести поиск ресурсов
Упражнение 5: Номер 1
Ответ:
(2) необходимо создание двух учетных записей для каждого пользователя: одну в создаваемом домене, другую - в существующем
(3) доступ учетных записей пользователей из существующего домена к ресурсам нового домена автоматически разрешен на уровне доверительных отношений между доменами
(4) почтовые ящики пользователей находятся на сервере существующего домена (LAN центрального офиса)
(7) пользователи, находясь внутри корпоративной сети, смогут получить доступ к ресурсам всей сети (регионы и центральный офис) согласно правам доступа
Номер 2
Ответ:
(1) данная схема предлагает консолидировать создаваемый домен и его дочерний домен в единый домен
(3) необходимо создание единой учетной записи для каждого пользователя в существующем и новом домене
(4) пользователи, находясь внутри корпоративной сети, не смогут получить доступ к ресурсам всей сети (регионы и центральный офис)
(5) доступ пользователей из существующего домена к ресурсам создаваемого домена должен быть запрещен выставлением прав доступа к объектам нового домена
(6) доступ пользователей из существующего домена к ресурсам создаваемого домена должен быть запрещен правилами на брандмауэре
(7) почтовые ящики пользователей находятся на сервере нового домена (LAN центрального офиса)
Номер 3
Ответ:
(4) домен, подготовленный для миграции, не может быть дочерним по отношению к создаваемому домену
(5) домен, подготовленный для миграции, может быть дочерним по отношению к создаваемому домену или корневому домену
(6) почтовые ящики пользователей находятся на сервере бывшего домена (LAN центрального офиса)
(7) пользователи, находясь как внутри корпоративной сети, так и в Интернету, смогут получить доступ к ресурсам всей сети (регионы и центральный офис) согласно правам доступа
(8) модернизация сетевой инфраструктуры компании, в которой планируется развернуть службу Active Directory
Упражнение 6: Номер 1
Ответ:
(3) владелец домена должен установить административную политику уровня домена (включая политики схем именования, проекта групп и т. д.), а затем делегировать права администраторам уровня OU
Номер 2
Ответ:
Номер 3
Ответ:
(1) для каждого из доменов, включенных в проект Active Directory, необходимо назначить владельца домена
(2) в большинстве случаев владельцы домена являются администраторами подразделений, в которых был определен домен
(4) в случае создания в домене OU-структуры высокого уровня, после которого задача создания подчиненных OU может быть передана администраторам уровня OU
(6) администраторы в каждом домене должны иметь высокую степень доверия, потому что их действия могут вызывать последствия на уровне леса
Аннотация: Приведены варианты построения единого леса службы Active Directory, указана возможность применения нескольких лесов и недостатки такой модели. Приведены варианты детализации доменной структуры Active Directory и кратко описан процесс назначения владельцев доменов
Цель лекции: Дать представление о возможных моделях построения лесов и соответствующей им детализации доменной структуры.
Лес - это группа из одного или нескольких деревьев доменов, которые не образуют единое пространство имен, но используют общие схему, конфигурацию каталогов, глобальный каталог и автоматически устанавливают двусторонние транзитивные доверительные отношения между доменами.
В сети всегда есть минимум один лес , создаваемый, когда в сети устанавливается первый контроллер домена . Первый домен становится корневым доменом леса .
Варианты построения леса
В данном разделе мы дадим описание различных моделей построения лесов Active Directory и проведем их сравнительный анализ .
- Вариант 1 "Единый лес, каждый регион - отдельное дерево".
- Вариант 2 "Единый лес, административный корневой домен, каждый регион - домен".
- Вариант 3 "Единый лес, каждый регион - дочерний домен центрального домена".
Под регионами в контексте данной лекции подразумеваются удаленные офисы компании, в которой планируется развернуть службу Active Directory .
Единый лес, каждый регион - отдельное дерево
Существует отдельное дерево с корневым доменом, хранящим группы Enterprise Admins и Schema Admins, что позволит гибко контролировать членство в этих группах и исключить присутствие в них по умолчанию всех администраторов центрального офиса (группа Admins корневого домена входит в группы Enterprise Admins, Schema Admins).
Разные деревья могут иметь различные пространства имен DNS. Корневые домены деревьев связаны транзитивными доверительными отношениями.
- пользователи могут просматривать ресурсы центрального офиса и регионов при соответствующих правах доступа к объектам Active Directory;
- возможность регистрации мобильных пользователей в любой точке организации;
- единый обмен в организации;
- повышенная защищенность - аутентификация по протоколу Kerberos , группы Enterprise Admins, Schema Admins находятся в отдельном корневом домене, Schema master находится в отдельном домене;
- самый короткий путь доверия.
- видимость списка доменов всей организации;
- для наличия права создания новых деревьев/доменов администратор должен присутствовать в группе Enterprise Admins;
- тиражирование конфигурации и схемы Active Directory для всех регионов;
- если в организации уже развернута структура Active Directory, то контроллеры домена в этой организации необходимо переустановить.
Единый лес, административный корневой домен, каждый регион - домен
Существуют общее дерево Active Directory для регионов и общая система именования, основанная на географическом принципе. Каждое региональное подразделение представлено доменом. Региональные домены добавляются как дочерние к корневому домену. Административные группы Enterprise Admins, Schema Admins, дающие их членам административные полномочия в лесу, вынесены в отдельный корневой домен.
Существует единое пространство доменных имен, дочерние домены наследуют DNS имя родительского домена. Также существует единая поисковая служба, позволяющая находить объекты в любом домене службы Active Directory.
- пользователи могут просматривать ресурсы центрального офиса и регионов при соответствующих правах доступа к объектам Active Directory;
- возможность регистрации мобильных пользователей в любой точке организации;
- единый обмен в организации;
- повышенная защищенность - аутентификация по протоколу Kerberos , группы Enterprise Admins, Schema Admins находятся в отдельном корневом домене, Schema master находится в отдельном домене.
- видимость списка доменов всей организации;
- для наличия права создания новых деревьев/доменов администратор должен присутствовать в группе Enterprise Admins;
- тиражирование конфигурации и схемы Active Directory для всех регионов;
- путь доверия длиннее.
Единый лес, каждый регион - дочерний домен центрального домена
В корневом домене наряду с группами Enterprise Admins и Schema Admins существуют остальные пользовательские учетные записи центрального офиса. Любой пользователь, попадающий в группу Admins, становится Enterprise Admins, так как группа Admins входит в группы Enterprise Admins и Schema Admins. Региональные домены становятся дочерними для корневого домена.
Существует единое пространство доменных имен, дочерние домены наследуют DNS имя родительского домена. Имеется единая поисковая служба, позволяющая находить объекты в любом домене службы Active Directory.
В среде Active Directory можно применить одну из следующих трех моделей проектирования леса:
Модель организационного леса
Модель леса ресурсов
Модель леса с ограниченным доступом
Скорее всего, потребуется использовать сочетание этих моделей для удовлетворения потребностей всех разных групп в Организации.
Модель организационного леса
В модели организационных лесов учетные записи пользователей и ресурсы содержатся в лесу и управляются независимо друг от друга. Организационный лес можно использовать для обеспечения автономности служб, изоляции служб или изоляции данных, если лес настроен для предотвращения доступа к любому пользователю за пределами леса.
Если пользователям в организационном лесу требуется доступ к ресурсам в других лесах (или наоборот), отношения доверия могут быть установлены между одним организационным лесом и другими лесами. Это дает администраторам возможность предоставлять доступ к ресурсам в другом лесу. На следующем рисунке показана модель организационного леса.
Каждый Active Directoryный проект содержит по крайней мере один организационный лес.
Модель леса ресурсов
В модели леса ресурсов для управления ресурсами используется отдельный лес. Леса ресурсов не содержат учетных записей пользователей, кроме тех, которые необходимы для администрирования службы, и те, которые необходимы для предоставления альтернативного доступа к ресурсам в этом лесу, если учетные записи пользователей в лесу организации становятся недоступными. Отношения доверия лесов устанавливаются таким образом, чтобы пользователи из других лесов могли обращаться к ресурсам, содержащимся в лесу ресурсов. На следующем рисунке показана модель леса ресурсов.
Леса ресурсов обеспечивают изоляцию служб, используемую для защиты областей сети, которые должны поддерживать состояние высокого уровня доступности. Например, если в вашей компании есть производственный механизм, который должен продолжать работать при возникновении проблем в оставшейся части сети, можно создать отдельный лес ресурсов для производственной группы.
Модель леса с ограниченным доступом
В модели леса с ограниченным доступом создается отдельный лес, содержащий учетные записи пользователей и данные, которые должны быть изолированы от остальной части Организации. Ограниченные леса доступа обеспечивают изоляцию данных в ситуациях, когда последствия компрометации данных проекта являются серьезными. На следующем рисунке показана модель ограниченного леса доступа.
Пользователям из других лесов не может быть предоставлен доступ к ограниченным данным, так как доверие не существует. В этой модели у пользователей есть учетная запись в лесу организации для доступа к общим ресурсам Организации и отдельная учетная запись пользователя в лесу ограниченного доступа для доступа к классифицированным данным. Эти пользователи должны иметь две отдельные рабочие станции, один из которых подключен к лесу организации, а другой — к лесу с ограниченным доступом. Благодаря этому администратор службы из одного леса может получить доступ к рабочей станции в лесу с ограниченным доступом.
В экстремальных случаях лес ограниченного доступа может поддерживаться в отдельной физической сети. Организации, работающие с классифицированными правительственными проектами, иногда поддерживают ограниченные леса доступа в отдельных сетях для удовлетворения требований безопасности.
Использование готовых библиотек, таких как Scikit-Learn, позволяет легко реализовать на Python сотни алгоритмов машинного обучения.

Как работает дерево решений
Дерево решений — интуитивно понятная базовая единица алгоритма случайный лес. Мы можем рассматривать его как серию вопросов да/нет о входных данных. В конечном итоге вопросы приводят к предсказанию определённого класса (или величины в случае регрессии). Это интерпретируемая модель, так как решения принимаются так же, как и человеком: мы задаём вопросы о доступных данных до тех пор, пока не приходим к определённому решению (в идеальном мире).
Базовая идея дерева решений заключается в формировании запросов, с которыми алгоритм обращается к данным. При использовании алгоритма CART вопросы (также называемые разделением узлов) определяются таким образом, чтобы ответы вели к уменьшению загрязнения Джини (Gini Impurity). Это означает, что дерево решений формирует узлы, содержащие большое количество образцов (из набора исходных данных), принадлежащих к одному классу. Алгоритм старается обнаружить параметры со сходными значениями.
Подробности, касающиеся загрязнения Джини, мы обсудим позже, а сейчас давайте создадим дерево решений, чтобы понять, как работает этот алгоритм.
Дерево решений для простой задачи
Начнём с проблемы простой бинарной классификации, изображённой на диаграмме.
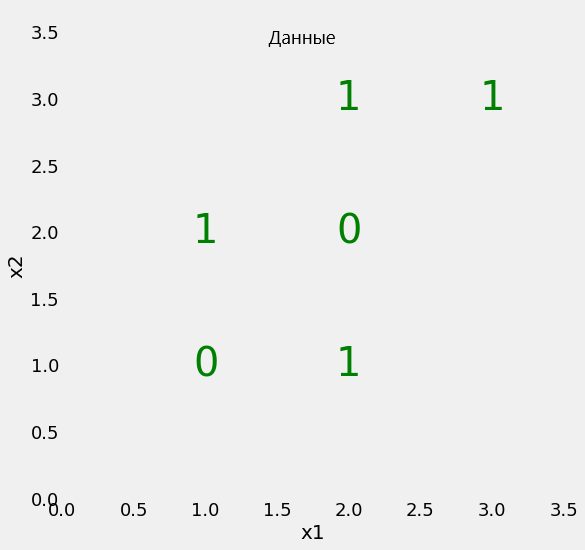
Наш набор данных имеет всего два параметра (две заданные переменные), x1 и x2, а также 6 образцов, несущих эти параметры. Образцы разделены метками на два класса. Хотя это простая задача, линейно классы разделить невозможно. Это означает, что мы не можем нарисовать на предложенной плоскости прямую линию, которая отделит один класс от другого.
В то же время мы можем разбить плоскость на участки (узлы) несколькими прямыми линиями. Именно это делает дерево решений в процессе тренировки. По сути дерево решений — нелинейная модель, создаваемая с помощью множества линейных ограничителей.
Мы используем Scikit-Learn, чтобы создать дерево решений и обучить ( fit ) его, используя наши данные.
Во время обучения мы используем и параметры, и метки, чтобы модель научилась сортировать данные на основе параметров. Для таких простых задач не используется тестовый набор данных. Но при тестировании модели мы сообщаем только параметры и сравниваем результат сортировки с теми метками, которые ожидали получить.
Можно проверить точность предсказаний нашей модели:
Разумеется, мы получим точность 100 %, так как сообщили модели правильные ответы ( y ) и не ограничивали глубину дерева. Но следует помнить, что подобная подгонка дерева решений под тренировочные данные может спровоцировать переобучение модели.
Визуализация дерева решений
Что же на самом деле происходит при обучении дерева решений? Хороший способ понять это — визуализация модели при помощи соответствующей функции Scikit-Learn (подробнее функция рассматривается в данной статье).

Во всех узлах, кроме листьев (цветные узлы без исходящих связей), содержится 5 частей:
- Вопрос о значении параметра образца. Ответ может принимать значение True или False . Это точка разделения узла, в зависимости от ответа определяется, в каком направлении вниз по дереву продвинется образец данных.
- Gini : средневзвешенное загрязнение Джини должно уменьшаться по мере того, как мы движемся вниз по дереву.
- Samples : количество прошедших через этот узел образцов.
- Value : отношение классов, прошедших через этот узел, выраженное в абсолютных числах. К примеру, верхний узел выделил 2 образца класса 0 и 4 образца класса 1.
- Class : класс большинства прошедших через узел образцов. Для листьев это прогнозируемое значение всех попадающих в эти узлы элементов.
Чтобы взглянуть на дерево решений под другим углом, мы спроецируем разделения модели на исходные данные.

Каждое разделение отображается одной линией, разделяющей образцы данных на узлы в соответствии со значением параметров. Поскольку максимальная глубина дерева не ограничена, разделение размещает каждый элемент в узел, содержащий только элементы того же класса. Позже мы рассмотрим, как идеальное разделение обучающих данных может привести к переобучению.
Загрязнение Джини
Теперь самое время рассмотреть концепцию загрязнения Джини (математика не так уж страшна, как кажется). Загрязнение Джини — вероятность неверной маркировки в узле случайно выбранного образца. К примеру, в верхнем (корневом) узле вероятность неверной классификации образца равна 44.4 %. Это можно вычислить с помощью уравнения:

Загрязнение Джини узла n равно 1 минус сумма отношений класса к общему количеству образцов pi, возведённых в квадрат, для каждого из множества классов J (в нашем случае это всего 2 класса). Звучит сложно, поэтому покажем, как вычисляется загрязнение Джини для корневого узла:
В каждом узле дерево решений ищет такое значение определённого параметра, которое приведёт к максимальному уменьшению загрязнения Джини. В качестве альтернативы для разделения узлов также можно использовать концепцию накопления информации.
Удельный вес загрязнения Джини для каждого узла равен отношению количества образцов, обработанных этим узлом, к количеству обработанных родительским узлом. Вы можете самостоятельно рассчитать загрязнение Джини для последующих уровней дерева и отдельных узлов, используя данные визуализации. Таким образом, эффективная модель строится на базовых математических операциях.
В итоге общевзвешенное загрязнение Джини последнего слоя сводится к нулю. Это значит, что каждый конечный узел содержит только образцы одного класса, и случайно выбранный образец не может быть неверно классифицирован. Звучит отлично, но помните, что это может быть сигналом того, что модель переобучена. Это происходит, потому что узлы смоделированы только на обучающих данных.
Переобучение, или почему лес лучше одного дерева
Может создаться впечатление, что для решения задачи хватило бы и одного дерева решений. Ведь эта модель не делает ошибок. Однако важно помнить, что алгоритм безошибочно отсортировал только тренировочные данные. Этого и следовало ожидать, поскольку мы указали верные ответы и не ограничили глубину дерева (количество слоёв). Но цель машинного обучения состоит в том, чтобы научить алгоритм обобщать полученную информацию и верно обрабатывать новые, ранее не встречавшиеся данные.
Переобучение происходит, когда мы используем очень гибкую модель (с высокой вместимостью), которая просто запоминает обучающий набор данных, подгоняя узлы под него. Проблема в том, что такая модель выявляет не только закономерности в данных, но и любой присутствующий в них шум. Такую гибкую модель часто называют высоковариативной, поскольку параметры, формирующиеся в процессе обучения (такие как структура дерева решений) будут значительно варьироваться в зависимости от обучающего набора данных.
С другой стороны, у недостаточно гибкой модели будет высокий уровень погрешности, поскольку она делает предположения относительно тренировочных данных (модель смещается в сторону предвзятых предположений о данных). К примеру, линейный классификатор предполагает, что данные распределены линейно. Из-за этого он не обладает достаточной гибкостью для соответствия нелинейным структурам. Ригидная модель может оказаться недостаточно ёмкой даже для соответствия тренировочным данным.
В обоих случаях — и при высокой вариативности, и при высокой погрешности — модель не сможет эффективно обрабатывать новые данные.
Поиск баланса между излишней и недостаточной гибкостью модели является ключевой концепцией машинного обучения и называется компромиссом между вариативностью и погрешностью (bias-variance tradeoff).
Алгоритм дерева решений переобучается, если не ограничить его максимальную глубину. Он обладает неограниченной гибкостью и может разрастаться, пока не достигнет состояния идеальной классификации, в которой каждому образцу из набора данных будет соответствовать один лист. Если вернуться назад к созданию дерева и ограничить его глубину двумя слоями (сделав только одно разделение), классификация больше не будет на 100 % верной. Мы уменьшаем вариативность за счёт увеличения погрешности.
Случайный лес
- Случайная выборка образцов из набора данных при построении деревьев.
- При разделении узлов выбираются случайные наборы параметров.
Случайная выборка тренировочных образцов
В процессе тренировки каждое дерево случайного леса учится на случайном образце из набора данных. Выборка образцов происходит с возмещением (в статистике этот метод называется бутстреппинг, bootstrapping). Это даёт возможность повторно использовать образцы одним и тем же деревом. Хотя каждое дерево может быть высоковариативным по отношению к определённому набору тренировочных данных, обучение деревьев на разных наборах образцов позволяет понизить общую вариативность леса, не жертвуя точностью.
При тестировании результат выводится путём усреднения прогнозов, полученных от каждого дерева. Подход, при котором каждый обучающийся элемент получает собственный набор обучающих данных (с помощью бутстреппинга), после чего результат усредняется, называется бэггинг (bagging, от bootstrap aggregating).
Случайные наборы параметров для разделения узлов
Вторая базовая концепция случайного леса заключается в использовании определённой выборки параметров образца для разделения каждого узла в каждом отдельном дереве. Обычно размер выборки равен квадратному корню из общего числа параметров. То есть, если каждый образец набора данных содержит 16 параметров, то в каждом отдельном узле будет использовано 4. Хотя обучение случайного леса можно провести и с полным набором параметров, как это обычно делается при регрессии. Этот параметр можно настроить в реализации случайного леса в Scikit-Learn.
Случайный лес сочетает сотни или тысячи деревьев принятия решений, обучая каждое на отдельной выборке данных, разделяя узлы в каждом дереве с использованием ограниченного набора параметров. Итоговый прогноз делается путём усреднения прогнозов от всех деревьев.
Чтобы лучше понять преимущество случайного леса, представьте следующий сценарий: вам нужно решить, поднимется ли цена акций определённой компании. У вас есть доступ к дюжине аналитиков, изначально не знакомых с делами этой компании. Каждый из аналитиков характеризуется низкой степенью погрешности, так как не делает каких-либо предположений. Кроме того, они могут получать новые данные из новостных источников.
Поэтому нужно не опираться на решение какого-то одного аналитика, а собрать вместе их прогнозы. Более того, как и при использовании случайного леса, нужно разрешить каждому аналитику доступ только к определённым новостным источникам, в надежде на то, что эффекты шумов будут нейтрализованы выборкой. В реальной жизни мы полагаемся на множество источников (никогда не доверяйте единственному обзору на Amazon). Интуитивно нам близка не только идея дерева решений, но и комбинирование их в случайный лес.
Алгоритм Random Forest на практике
Настало время реализовать алгоритм случайного леса на языке Python с использованием Scikit-Learn. Вместо того чтобы работать над элементарной теоретической задачей, мы используем реальный набор данных, разбив его на обучающий и тестовый сеты. Тестовые данные мы используем для оценки того, насколько хорошо наша модель справляется с новыми данными, что поможет нам выяснить уровень переобучения.
Набор данных
Мы попробуем рассчитать состояние здоровья пациентов в бинарной системе координат. В качестве параметров мы используем социально-экономические и персональные характеристики субъектов. В качестве меток мы используем 0 для плохого здоровья и 1 для хорошего. Этот набор данных был собран Центром по Контролю и Предотвращению Заболеваний и размещён в свободном доступе.
Как правило 80 % работы над научным проектом заключается в изучении, очистке и синтезировании параметров из сырых данных (подробнее узнать можно здесь). Однако в этой статье мы сосредоточимся на построении модели.
В данном примере мы сталкиваемся с задачей несбалансированной классификации, поэтому простой параметр точности модели не отобразит истинной её производительности. Вместо этого мы используем площадь под кривой операционных характеристик приёмника (ROC AUC), измерив от 0 (в худшем случае) до 1 (в лучшем случае) со случайным прогнозом на уровне 0,5. Мы также можем построить указанную кривую, чтобы проанализировать модель.
В этом Jupyter notebook содержатся реализации и дерева решений, и случайного леса, но здесь мы сфокусируемся на последнем. После получения данных мы можем создать и обучить этот алгоритм следующим образом:
После нескольких минут обучения модель будет готова выдавать прогнозы для тестовых данных:
Мы рассчитаем прогнозы классификации ( predict ) наряду с прогностической вероятностью ( predict_proba ), чтобы вычислить ROC AUC.
Результаты
Итоговое тестирование ROC AUC для случайного леса составило 0.87, в то время как для единичного дерева с неограниченной глубиной — 0.67. Если вернуться к результатам обработки тренировочных данных, обе модели покажут эффективность, равную 1.00 на ROC AUC. Этого и следовало ожидать, ведь мы предоставили готовые ответы и не ограничивали максимальную глубину каждого дерева.
Несмотря на то, что случайный лес переобучен (показывает на тренировочных данных лучшую производительность, чем на тестовых), он всё же гораздо больше способен к обобщениям, чем одиночное дерево. При низкой вариативности (хорошо) случайный лес наследует от одиночного дерева решений низкую склонность к погрешности (что тоже хорошо).
Мы можем визуализовать кривую ROC для одиночного дерева (верхняя диаграмма) и для случайного леса в целом (нижняя диаграмма). Кривая лучшей модели стремится вверх и влево:


Случайный лес значительно превосходит по точности одиночное дерево.
Ещё один способ оценить эффективность построенной модели — матрица погрешностей для тестовых прогнозов.

На диаграмме верные прогнозы, сделанные моделью, отображаются в верхнем левом углу и в нижнем правом, а неверные в нижнем левом и верхнем правом. Подобные диаграммы мы можем использовать, чтобы оценить, достаточно ли проработана наша модель и готова ли она к релизу.
Значимость параметра
Значимость параметра в случайном лесу — это суммарное уменьшение загрязнения Джини во всех узлах, использующих этот параметр для разделения. Мы можем использовать это значение для определения опытным путём, какие переменные более всего принимаются во внимание нашей моделью. Мы можем рассчитать значимость параметров в уже обученной модели и экспортировать результаты этих вычислений в Pandas DataFrame следующим образом:
Значимость параметра даёт лучшее понимание задачи, показывая, какие переменные лучше всего разделяют набор данных на классы. В данном примере переменная DIFFWALK , отображающая, что пациент испытывает затруднения при ходьбе, является самым значимым параметром.
Рассматриваемая величина может также использоваться для синтезирования дополнительных параметров, объединяющих несколько наиболее важных. При отборе параметров их значимость может указать на те, которые можно удалить из набора данных без ущерба производительности модели.
Визуализация единичного дерева леса
Мы также можем визуализовать единичное дерево случайного леса. В данном случае нам придётся ограничить его глубину, иначе оно может оказаться слишком большим для преобразования в изображение. Для этого изображения глубина была ограничена до 6 уровней. Результат всё равно слишком велик, однако, внимательно его изучив, мы можем понять, как работает наша модель.

Следующие шаги
Следующим шагом будет оптимизация случайного леса, которую можно выполнить через случайный поиск, используя RandomizedSearchCV в Scikit-Learn. Оптимизация подразумевает поиск лучших гиперпараметров для модели на текущем наборе данных. Лучшие гиперпараметры будут зависеть от набора данных, поэтому нам придётся проделывать оптимизацию (настройку модели) отдельно для каждого набора.
Можно рассматривать настройку модели как поиск лучших установок для алгоритма машинного обучения. Примеры параметров, которые можно оптимизировать: количество деревьев, их максимальная глубина, максимальное количество параметров, принимаемых каждым узлом, максимальное количество образцов в листьях.
Реализацию случайного поиска для оптимизации модели можно изучить в Jupyter Notebook.
Полностью рабочий образец кода
Приведённый ниже код создан с помощью repl.it и представляет полностью рабочий пример создания алгоритма случайного леса на Python. Можете самостоятельно его запустить и попробовать поэкспериментировать, изменяя код (загрузка пакетов может занять некоторое время).
Заключение и выводы
Хотя мы действительно можем создавать мощные модели машинного обучения на Python, не понимая принципов их работы, знание основ позволит работать более эффективно. В этой статье мы не только построили и использовали на практике алгоритм случайного леса, но и разобрали, как работает эта модель.
Мы изучили работу дерева принятия решений, элемента, из которого состоит случайный лес, и увидели, как можно преодолеть высокую вариативность единичного дерева, комбинируя сотни таких деревьев в лес. Случайный лес работает на принципах случайной выборки образцов, случайного набора параметров и усреднения прогнозов.
Читайте также: