
Генеральная совокупность это кратко
Обновлено: 03.05.2024
Понятие выборки используется, когда надо изучить какие-либо свойства совокупности объектов. Свойства объектов можно разделить на качественные и количественные.
Пусть нам необходимо изучить совокупность партии сметаны. Тогда качественным признаком может служить срок её годности, а количественным процент содержания жиров в данной сметане.
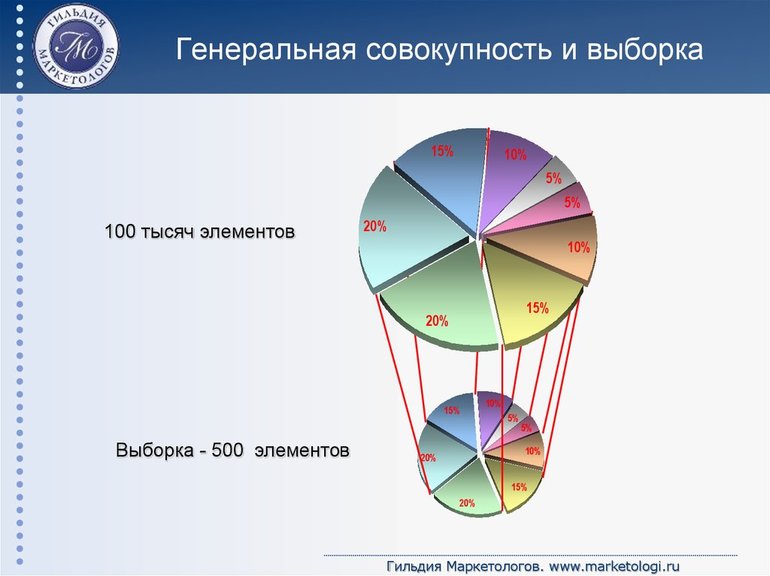
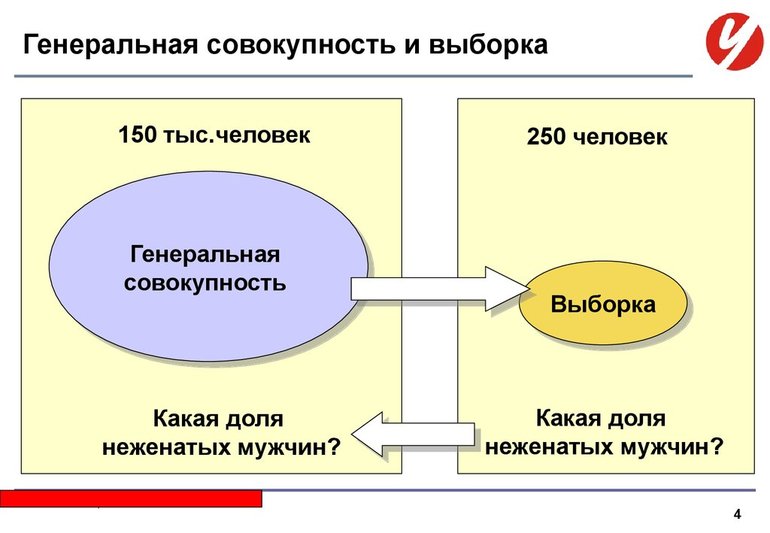
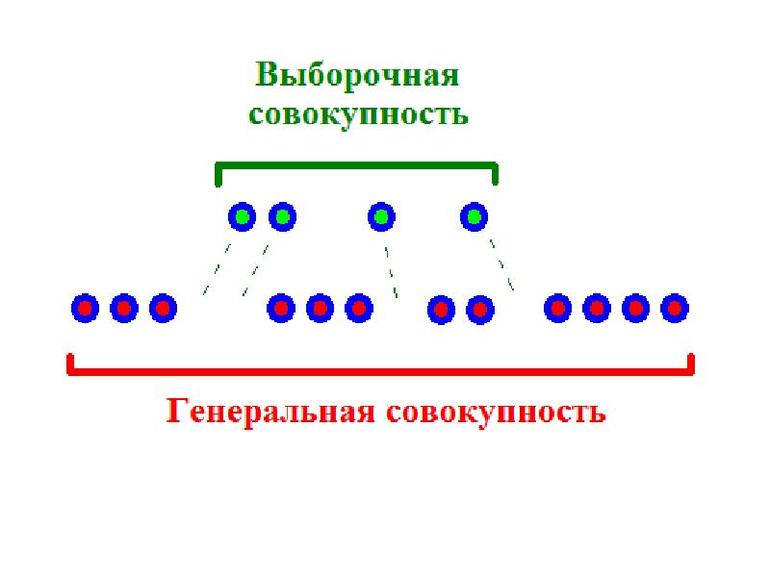
Совокупность или выборка может быть разделена на генеральную и выборочную.
Генеральная совокупность -- совокупность случайно отобранных объектов данного вида, над которыми проводят наблюдения с целью получения конкретных значений случайной величины, проводимых в неизменных условиях при изучении одной случайной величины данного вида.
Выборочная совокупность -- часть отобранных объектов из генеральной совокупности.
С понятием совокупности также связано понятие объема данной совокупности.
Объем совокупности -- число объектов этой совокупности.
Понятие объема совокупности относится и к выборочной, и к генеральной совокупности.
Пусть из партии 100 пачек масла для исследования выбрано 10 пачек. Тогда объем генеральной совокупности $N=100$, а объем выборки $n=10$.
Исходя из первых двух определений, очевидно, что всегда выполняется неравенство $N>n$
Готовые работы на аналогичную тему
Помимо этих двух совокупностей выделяют также репрезентативную или представительную выборку.
Репрезентативная (представительная) выборка -- выборка, в которой все объекты выбраны случайно и генеральной совокупности, то есть каждый объект генеральной совокупности имеет одинаковую вероятность попасть в выборку.
Выборка также может быть повторной и бесповторной.
Повторная выборка -- выборка, при которой выбранный объект возвращается обратно в генеральную совокупность перед выбором следующего объекта для исследования.
Бесповторная выборка -- выборка, при которой объект не возвращается обратно в генеральную совокупность перед выбором очередного объекта для исследования.
Способы отбора
Рассмотрим теперь различные способы отбора (схема 1).

Рисунок 1. Способы отбора.
Разберемся теперь с каждым понятием по отдельности.
Простой случайный бесповторный отбор -- отбор, при котором объекты из генеральной совокупности выбираются по одному и не возвращаются обратно в генеральную совокупность.
Простой случайный повторный отбор -- отбор, при котором объекты из генеральной совокупности выбираются по одному и возвращаются обратно в генеральную совокупность.
Типический отбор -- отбор, при котором выборка производится не из всей генеральной совокупности, а из каждой его части по отдельности.
К примеру, если сметана произведена на трех разных заводах, то выборка делается по каждому заводу отдельно.
Механический отбор -- отбор, при котором генеральная совокупность делится на такое количество групп сколько объектов для исследования необходимо выбрать.
Пусть из партии 100 пачек масла нужно для исследования отобрать $10\%$. Тогда выбирается по одной пачке из каждых 10 пачек масла.
. Отметим, что при таком отборе выборка не всегда получается репрезентативной.
Серийный отбор -- отбор, при котором выборка происходит из генеральной совокупности не по одному, а сериями.
. На практике часто применяется комбинированный отбор, при котором используются сразу несколько видов отборов, перечисленных выше.
Формулы, связанные с понятием выборки
Введем несколько формул:
Отметим, что $\sum=N$
- Генеральная средняя при бесповторной выборке:
- Выборочная средняя при повторной выборке:
Отметим, что $\sum=n$
- Выборочная средняя при бесповторной выборке:
- Ошибка репрезентативности:
Пример задачи на нахождение ошибки репрезентативности
Пусть в магазине 20 видов глазированных сырков. Средняя цена 1 вида сырка составляет 10,4 рублей. Сырков с начинкой из этих видов составляет $25\%$ и средняя цена каждого вида с начинкой равняется 11 рублей. Найти ошибку репрезентативности данной выборки.
10,4 -- это генеральная средняя величина, то есть $\overline=10,4$.
Так как сырки с начинкой составляют $25\%$, то сырков с начинкой$20\cdot 0,25=5$ видов.
Генеральная совокупность, генеральная выборка (от лат. generis — общий, родовой)(в англ. терминологии — population) — совокупность всех объектов (единиц), относительно которых учёный намерен делать выводы при изучении конкретной проблемы.
Генеральная совокупность состоит из всех объектов, которые подлежат изучению. Состав генеральной совокупности зависит от целей исследования. Иногда генеральная совокупность - это все население определённого региона (например, когда изучается отношение потенциальных избирателей к кандидату), чаще всего задаётся несколько критериев, определяющих объект исследования. Например, женщины 10-89 лет, использующие крем для рук определённых марок не реже раза в неделю, и имеющие доход не ниже $150 на одного члена семьи.
Источник
См. также
- Выборочный метод
- Социология
- Экспериментальная психология
Wikimedia Foundation . 2010 .
Полезное
Смотреть что такое "Генеральная совокупность" в других словарях:
Генеральная совокупность — вся изучаемая выборочным методом статистическая совокупность объектов и/или явлений общественной жизни, имеющих общие качественные признаки или количественные переменные. По английски: General sample См. также: Статистические совокупности… … Финансовый словарь
Генеральная Совокупность — См. Совокупность генеральная Словарь бизнес терминов. Академик.ру. 2001 … Словарь бизнес-терминов
ГЕНЕРАЛЬНАЯ СОВОКУПНОСТЬ — англ. general sample; нем. Grundgesamtheit. Вся изучаемая выборочным методом статист, совокупность объектов и/или явлений обществ, жизни (единиц отбора), имеющих общие качественные признаки или количественные переменные. см. ВЫБОРКА, ВЫБОРКИ… … Энциклопедия социологии
генеральная совокупность — – это (как правило, лишь воображаемое) полное собрание объектов (людей, животных, растений или вещей), являющееся источником данных. Она представляет все множество статистических единиц (группу интересующих нас предметов). Приведенный пассаж… … Словарь социологической статистики
ГЕНЕРАЛЬНАЯ СОВОКУПНОСТЬ — заданное множество, конечное или бесконечное. Любой случайный эксперимент можно интерпретировать как случайный выбор индивидуума из бесконечной Г. с. При статистическом изучении из Г. с., характеризуемой функцией распределения вероятностей,… … Геологическая энциклопедия
Генеральная совокупность — [general population] см. Выборочные методы … Экономико-математический словарь
ГЕНЕРАЛЬНАЯ СОВОКУПНОСТЬ — см. Выборочное исследование. Большой психологический словарь. М.: Прайм ЕВРОЗНАК. Под ред. Б.Г. Мещерякова, акад. В.П. Зинченко. 2003 … Большая психологическая энциклопедия
(генеральная) совокупность — 1.3.1 (генеральная) совокупность Множество всех рассматриваемых единиц продукции (по 2.3 ГОСТ Р 50779.10). Примечание Если рассматривают случайную величину, то для определения генеральной совокупности ее значений применяют распределение… … Словарь-справочник терминов нормативно-технической документации
генеральная совокупность — tiriamoji visuma statusas T sritis chemija apibrėžtis Tiriamasis objektas ar jų grupė. atitikmenys: angl. general population; population rus. генеральная совокупность; совокупность … Chemijos terminų aiškinamasis žodynas
Генеральная совокупность — это набор объектов, для которых планируется изучить определённую проблему и принять выводы. Это понятие в целом включает в себя всё, что планируется изучать. Вывод зависит от целей, поставленных исследователем. Например, при изучении социальной концепции перед выборами вся общественность определённой области имеет возможность рассматриваться как общество в целом. Для определения объекта исследования, как правило, выдвигается ряд критериев.

Терминология и её концепция
Население — статистическая группа, статистическая масса, что представляет собой совокупность любых элементов, схожих с точки зрения специфических черт (но не идентичных), которые подлежат статистическому обследованию. Изучение всей статистической совокупности будет слишком сложным по времени, техническим и финансовым причинам, поэтому отбирается выборка, по которой будет проводиться исследование .
Исследуемая популяция должна быть однозначно определена и отделена от других элементов. Это достигается путём указания цели исследования (кого или что следует включить в обследуемое население).
Генеральная совокупность в статистике — это всегда сбор данных. Статистической единицей является каждый элемент населения. Различают единицы, включённые в исследуемую совокупность, что характеризуется определёнными статистическими признаками, то есть функциями, которые присваиваются элементам совокупности.
Статистические особенности можно разделить на большие группы. Фиксированные являются общими для всех единиц исследуемого населения. Они не подлежат статистической проверке, а только определяют включение отдельных лиц в определённую группу населения. Однако это не означает, что статистическая характеристика, которая была в одном исследовании, не может быть переменной в другом.
Постоянные символы можно разделить:
- субстанциональные признаки различны по своей природе, они определяют, что следует исследовать;
- пространственные особенности определяют место и район, или где расположены исследовательские единицы;
- временные характеристики определяют момент и время, то есть, когда проводится экспертиза.
Из генеральной совокупности формируются переменные. Это особенности, которые отличаются от отдельных статистических единиц, что имеют более одного варианта. Эта переменная может иметь конечное или бесконечное количество вариантов. Они подлежат статистическому обследованию.
Переменные функции можно разделить:
- количественные, измеримые по-разному, сюда можно включить: возраст, рост и вес;
- качественно неизмеримые, сюда можно отнести: группу крови, цвет волос и пол.
Численность населения представляет собой любой конкретный счёт статистики. Один и тот же статистический аспект обладает способностью быть однородным на одной основе и неоднородным на другой.
В статистической совокупности есть дисперсия, и различия между одной единицей населения и другой часто рассматриваются как количественные. Эти конфигурации значений данных различных популяционных единиц называются вариантами.
Вариация — это количественное изменение степени (для характеристики) при переходе от одной единицы населения к другой. Линия — это свойство, особенность единиц, объектов и явлений, которые можно отслеживать или измерять. Символы делятся на количественные и качественные. Разнообразие и изменчивость значения в отдельных единицах населения называется вариацией.

Атрибутные (качественные) аспекты не поддаются числовому выражению (состав населения по полу). Количественные признаки имеют числовое распространение (состав населения, отклонение по возрасту).
Мера обобщается для количественной оценки высококачественных данных или качеств единиц, для определения мотивированного показателя в определённых критериях времени и пространства.
Система характеристик предоставляет набор характеристик, которые показывают исследуемый вид со всех сторон.
Например, зарплата исследуется как:
- оплата труда;
- статистика по сотруднику;
- качественная регулярность расчёта;
- знак вариации, количество цифр.
Математическая статистика
Этот вид статистики — раздел прикладной арифметики, который рассматривает способы поиска законов и данных случайных величин на основе результатов исследований и экспериментов. Стратификация предполагает разделение полученных данных на отдельные группы.
Основные задачи математической статистики:

- Создание методов сбора и обработки групп статистическим материалом, полученным методом исследования случайных процессов.
- Разработка методов анализа статистических данных.
- Получение выводов из исследования.
Проверка статистических данных включает оценку вероятности действия, распределение функций или плотности возможностей, оценку характеристик популярного распределения, взаимосвязи между случайными переменными.
Математическая статистика может увеличить данные маркетинга и основана на учении о возможностях и, в свою очередь, служит основой для разработки способов обработки и анализа статистических результатов в определённых областях человеческой работы.
Общественность и выбор
Естественно, генеральная совокупность должна быть конечным или неограниченным источником данных, в противном случае набор объектов, их элементов, не ограничен. Выбор, как правило, относится к коллекции случайно отобранных объектов из совокупности. Он должен быть репрезентативным, и может достаточно хорошо отражать жизнь населения.
Используют разные способы выбора:
Количество объектов в совокупности и количество выбранных называются размерами объединённого набора в соответствии с этим.
Способ сбора
Фактически известно, что социологические научные соглашения связаны не с текучей спонтанностью жизни, а с данными, санкционированными в соответствии с конкретными правилами символов. Согласно протяжению информации, значения переменных, присвоенных единицам, относятся к средним объектам, которые создают различные и часто необычные конфигурации в пространстве символов, давая исследователю возможность строить обобщающие суждения о реальности. Полученные данные относятся к оформлению документов (анкет, опросных листов, протоколов исследований и т. д. ).
Основные методы сбора информации
Методы социологического исследования, конкретные когнитивные ориентации, схемы, инструменты, используемые исследователями при изучении объекта можно разделить на группы: совместные и социологические, что могут возвращаться.
Своеобразные социологические способы:

Таким образом, нужно понять, что называется генеральной совокупностью в целом. Это собранные данные всех единиц или границ объектов, в отношении которых планируется изучить конкретную проблему и принять выводы.
- Генеральная совокупность (от лат. generis — общий, родовой) — совокупность всех объектов (единиц), относительно которых предполагается делать выводы при изучении конкретной задачи.
Связанные понятия
Выборка или выборочная совокупность — часть генеральной совокупности элементов, которая охватывается экспериментом (наблюдением, опросом).
То́чечная оце́нка в математической статистике — это число, оцениваемое на основе наблюдений, предположительно близкое к оцениваемому параметру.
Доверительный интервал — термин, используемый в математической статистике при интервальной оценке статистических параметров, более предпочтительной при небольшом объёме выборки, чем точечная. Доверительным называют интервал, который покрывает неизвестный параметр с заданной надёжностью.
Статистический критерий — строгое математическое правило, по которому принимается или отвергается та или иная статистическая гипотеза с известным уровнем значимости. Построение критерия представляет собой выбор подходящей функции от результатов наблюдений (ряда эмпирически полученных значений признака), которая служит для выявления меры расхождения между эмпирическими значениями и гипотетическими.
Проверка статистических гипотез является содержанием одного из обширных классов задач математической статистики.
Упоминания в литературе
Если отталкиваться от классификации Д. Кэмпбелла [Кэмпбелл, 1996], то этнопсихологические исследования преимущественно соответствуют доэкспериментальному дизайну. По сути, этнопсихологические исследования, в которых изучаются культурно-психологические особенности одной группы, соответствуют схеме изучения единичного случая, т. е. это тот вариант исследования, который обозначен Д. Кэмпбеллом как доэксперимент. Что может рассматривать в данном случае исследователь? Прежде всего установление характерной частоты встречаемости событий, явлений, объектов. Встречаются ли в выборке люди с определенными личностными особенностями? Каков способ решения различных задач в данной культуре? Как протекают процессы логического мышления у представителей данной культуры? В данном исследовательском дизайне возможны также классификации людей в рамках выборки на какие-либо группы, классы с последующим распространением (при достаточной репрезентативности выборки) полученных результатов на генеральную совокупность . Для доэкспериментального дизайна исследования применительно к этнопсихологии характерны следующие виды гипотез: а) о существовании каких-либо психологических явлений, характеристику представителей определенной этнической группы или культуры; б) о соотношении частот встречаемости объектов (например, людей с определенными характеристиками личности) или явлений
Как и у любого метода, здесь существуют и достоинства, и недостатки. К достоинствам следует отнести возможность для участников фокус-группы честно и свободно высказываться по определенной проблеме, достоверность результатов, многообразие направлений, по которым может быть использован данный метод, возможность изучения респондентов. Среди недостатков данного метода – его нерепрезентативность (слишком маленькая группа участников по отношению к генеральной совокупности в целом) и его относительно высокая стоимость.
Выборочная совокупность (респонденты), т. е. лица, подлежащие опросу или другим методам исследования по изучаемым параметрам должны приближаться к показателям генеральной совокупности . Так социологи могут работать на малых выборках, когда исследование не превышает 30 единиц наблюдения, и на больших выборках, составляющих несколько тысяч единиц наблюдения. При исследовании локальных объектов (предприятие) могут применяться сплошные или 50 %-ные выборки, когда опрашивается каждый второй. Чем более однороден объект, тем меньше объем выборки.
Связанные понятия (продолжение)
Статистика — измеримая числовая функция от выборки, не зависящая от неизвестных параметров распределения элементов выборки.
Несмещённая оце́нка в математической статистике — это точечная оценка, математическое ожидание которой равно оцениваемому параметру.
Апостерио́рная вероя́тность — условная вероятность случайного события при условии того, что известны апостериорные данные, т.е. полученные после опыта.
Нулевая гипотеза — принимаемое по умолчанию предположение о том, что не существует связи между двумя наблюдаемыми событиями, феноменами. Так, нулевая гипотеза считается верной до того момента, пока нельзя доказать обратное. Опровержение нулевой гипотезы, то есть приход к заключению о том, что связь между двумя событиями, феноменами существует, — главная задача современной науки. Статистика как наука даёт чёткие условия, при наступлении которых нулевая гипотеза может быть отвергнута.
Кванти́ль в математической статистике — значение, которое заданная случайная величина не превышает с фиксированной вероятностью. Если вероятность задана в процентах, то квантиль называется процентилем или перцентилем (см. ниже).
Ме́тод максима́льного правдоподо́бия или метод наибольшего правдоподобия (ММП, ML, MLE — англ. maximum likelihood estimation) в математической статистике — это метод оценивания неизвестного параметра путём максимизации функции правдоподобия. Основан на предположении о том, что вся информация о статистической выборке содержится в функции правдоподобия.
Независимая переменная — в эксперименте переменная, которая намеренно манипулируется или выбирается экспериментатором с целью выяснить её влияние на зависимую переменную.
Сре́днее значе́ние — числовая характеристика множества чисел или функций (в математике); — некоторое число, заключённое между наименьшим и наибольшим из их значений.
Состоя́тельная оце́нка в математической статистике — это точечная оценка, сходящаяся по вероятности к оцениваемому параметру.
Дисперсионный анализ — метод в математической статистике, направленный на поиск зависимостей в экспериментальных данных путём исследования значимости различий в средних значениях. В отличие от t-критерия, позволяет сравнивать средние значения трёх и более групп. Разработан Р. Фишером для анализа результатов экспериментальных исследований. В литературе также встречается обозначение ANOVA (от англ. ANalysis Of VAriance).
Статистический вывод (англ. statistical inference), также называемый индуктивной статистикой (англ. inferential statistics, inductive statistics) — обобщение информации из выборки для получения представления о свойствах генеральной совокупности.
Ковариа́ция (корреляционный момент, ковариационный момент) — в теории вероятностей и математической статистике мера линейной зависимости двух случайных величин.
Временно́й ряд (или ряд динамики) — собранный в разные моменты времени статистический материал о значении каких-либо параметров (в простейшем случае одного) исследуемого процесса. Каждая единица статистического материала называется измерением или отсчётом, также допустимо называть его уровнем на указанный с ним момент времени. Во временном ряде для каждого отсчёта должно быть указано время измерения или номер измерения по порядку. Временной ряд существенно отличается от простой выборки данных, так.
Тест отноше́ния правдоподо́бия (англ. likelihood ratio test, LR) — статистический тест, используемый для проверки ограничений на параметры статистических моделей, оценённых на основе выборочных данных. Является одним из трёх базовых тестов проверки ограничений наряду с тестом множителей Лагранжа и тестом Вальда.
Автокорреляция — статистическая взаимосвязь между последовательностями величин одного ряда, взятыми со сдвигом, например, для случайного процесса — со сдвигом по времени.
В математической статистике семплирование — обобщенное название методов манипулирования начальной выборкой при известной цели моделирования, которые позволяют выполнить структурно-параметрическую идентификацию наилучшей статистической модели стационарного эргодического случайного процесса.
Функция потерь — функция, которая в теории статистических решений характеризует потери при неправильном принятии решений на основе наблюдаемых данных. Если решается задача оценки параметра сигнала на фоне помех, то функция потерь является мерой расхождения между истинным значением оцениваемого параметра и оценкой параметра.
Логистическая регрессия или логит-регрессия (англ. logit model) — это статистическая модель, используемая для прогнозирования вероятности возникновения некоторого события путём подгонки данных к логистической кривой.
Ме́тод моме́нтов — метод оценки неизвестных параметров распределений в математической статистике и эконометрике, основанный на предполагаемых свойствах моментов (Пирсон, 1894 г.). Идея метода заключается в замене истинных соотношений выборочными аналогами.
Распределение вероятностей — это закон, описывающий область значений случайной величины и вероятности их исхода (появления).
Усло́вное распределе́ние в теории вероятностей — это распределение случайной величины при условии, что другая случайная величина принимает определённое значение.
Ковариацио́нная ма́трица (или ма́трица ковариа́ций) в теории вероятностей — это матрица, составленная из попарных ковариаций элементов одного или двух случайных векторов.
Байесовская вероятность — это интерпретация понятия вероятности, используемая в байесовской теории. Вероятность определяется как степень уверенности в истинности суждения. Для определения степени уверенности в истинности суждения при получении новой информации в байесовской теории используется теорема Байеса.
Гетероскедастичность (англ. heteroscedasticity) — понятие, используемое в прикладной статистике (чаще всего — в эконометрике), означающее неоднородность наблюдений, выражающуюся в неодинаковой (непостоянной) дисперсии случайной ошибки регрессионной (эконометрической) модели. Гетероскедастичность противоположна гомоскедастичности, означающей однородность наблюдений, то есть постоянство дисперсии случайных ошибок модели.
Сре́днее арифмети́ческое (в математике и статистике) множества чисел — число, равное сумме всех чисел множества, делённой на их количество. Является одной из наиболее распространённых мер центральной тенденции.
Ординалистская (порядковая) теория полезности основывается на том, что предпочтения индивидуума относительно предлагаемых к выбору альтернатив не могут измеряться количественно, а только сравниваться, то есть одна альтернатива хуже или лучше другой. Альтернативой данной теории является кардиналистская (количественная) теория полезности.
В теории вероятностей два случайных события называются независимыми, если наступление одного из них не изменяет вероятность наступления другого. Аналогично, две случайные величины называют независимыми, если известное значение одной из них не дает информации о другой.
Модель бинарного выбора — применяемая в эконометрике модель зависимости бинарной переменной (принимающей всего два значения — 0 и 1) от совокупности факторов. Построение обычной линейной регрессии для таких переменных теоретически некорректно, так как условное математическое ожидание таких переменных равно вероятности того, что зависимая переменная примет значение 1, а линейная регрессия допускает и отрицательные значения и значения выше 1. Поэтому обычно используются некоторые интегральные функции.
Фа́кторный анализ — многомерный метод, применяемый для изучения взаимосвязей между значениями переменных. Предполагается, что известные переменные зависят от меньшего количества неизвестных переменных и случайной ошибки.
Частотное распределение — метод статистического описания данных (измеренных значений, характерных значений). Математически распределение частот является функцией, которая в первую очередь определяет для каждого показателя идеальное значение, так как эта величина обычно уже измерена. Такое распределение можно представить в виде таблицы или графика, моделируя функциональные уравнения. В описательной статистике частота распределения имеет ряд математических функций, которые используются для выравнивания.
Условное математическое ожидание в теории вероятностей — это среднее значение случайной величины относительно условного распределения.
Многоме́рное норма́льное распределе́ние (или многоме́рное га́уссовское распределе́ние) в теории вероятностей — это обобщение одномерного нормального распределения. Случайный вектор, имеющий многомерное нормальное распределение, называется гауссовским вектором.
Качественная, дискретная, или категорийная переменная — это переменная, которая может принимать одно из ограниченного и, обычно, фиксированного числа возможных значений, назначая каждую единицу наблюдения определённой группе или номинальной категории на основе некоторого качественного свойства. В информатике и некоторых других ветвях математики качественные переменные называются перечислениями или перечисляемыми типами. Обычно (хотя не в этой статье), каждое из возможных значений качественной переменной.
Задача классифика́ции — задача, в которой имеется множество объектов (ситуаций), разделённых некоторым образом на классы. Задано конечное множество объектов, для которых известно, к каким классам они относятся. Это множество называется выборкой. Классовая принадлежность остальных объектов неизвестна. Требуется построить алгоритм, способный классифицировать (см. ниже) произвольный объект из исходного множества.
Наи́вный ба́йесовский классифика́тор — простой вероятностный классификатор, основанный на применении теоремы Байеса со строгими (наивными) предположениями о независимости.
Фу́нкция распределе́ния в теории вероятностей — функция, характеризующая распределение случайной величины или случайного вектора; вероятность того, что случайная величина X примет значение, меньшее или равное х, где х — произвольное действительное число. При соблюдении известных условий (см. ниже) полностью определяет случайную величину.
Т-критерий Вилкоксона — (также используются названия Т-критерий Уилкоксона, критерий Вилкоксона, критерий знаковых рангов Уилкоксона, критерий суммы рангов Уилкоксона) непараметрический статистический тест (критерий), используемый для проверки различий между двумя выборками парных или независимых измерений по уровню какого-либо количественного признака, измеренного в непрерывной или в порядковой шкале.. Впервые предложен Фрэнком Уилкоксоном. Другие названия — W-критерий Вилкоксона, критерий знаковых.
Метод инструментальных переменных (ИП, IV — Instrumental Variables) — метод оценки параметров регрессионных моделей, основанный на использовании дополнительных, не участвующих в модели, так называемых инструментальных переменных. Метод применяется в случае, когда факторы регрессионной модели не удовлетворяют условию экзогенности, то есть являются зависимыми со случайными ошибками. В этом случае, оценки метода наименьших квадратов являются смещенными и несостоятельными.
Упоминания в литературе (продолжение)
1. Мониторинг здоровья населения Вологодской области и условий его охраны и укрепления. Обследование проходило ежегодно в период с 1999 по 2008 г. на базе Института социально-экономического развития территорий РАН (ИСЭРТ РАН) в форме стандартизованного интервью в городах Вологде и Череповце, а также в восьми районах Вологодской области (Бабаевский, Великоустюгский, Вожегодский, Грязовецкий, Кирилловский, Никольский, Тарногский, Шекснинский). Объем ежегодной выборки – 1500 респондентов. Тип выборки: районирование с пропорциональным размещением единиц наблюдения, квотная по полу и возрасту в соответствии с генеральной совокупностью . Репрезентативность выборки обеспечивалась соблюдением следующих условий: пропорций между городским и сельским населением; пропорций между жителями населенных пунктов различных типов (сельские населенные пункты, малые и средние города); половозрастной структуры взрослого населения области. Величина случайной ошибки выборки составляет 3 % при доверительном интервале 4–5 %. Техническая обработка информации производилась в программах SPSS и Excel.
Приведенная дефиниция приемлема, видимо, в отношении управления во всех его трех сферах (А. И. Берг98). Социальное управление вычленяется из генеральной совокупности по ясно различаемому признаку – сфере функционирования. Следует, однако, определиться с соотношением социального и государственного управления. Государственное управление – это составная часть социального управления, вычлененная из генеральной совокупности по двум следующим сопряженным между собой признакам: а) в зависимости от субъекта, осуществляющего управляющие воздействия и б) от применяемых им методов внешних управляющих воздействий99. Понятие государственного управления в рамках традиционных правовых наук не совпадает с одноименным понятием в рамках управления социальными системами, это несовпадение порождено не только различием в методах исследования, но и несовпадением при совпадающем объекте – предмета исследования.
Вся совокупность единиц, из которых производится отбор, называется генеральной совокупностью . Часть единиц генеральной совокупности, отобранная в случайном порядке, составляет выборочную совокупность. Характеристиками генеральной и выборочной совокупности служат доля и средняя величина, а также дисперсия и среднее квадратическое отклонение. Средняя величина является характеристикой количественных признаков, а дол я – характеристикой альтернативных признаков.
Математическая статистика – наука о математических методах систематизации и использования статистических данных для решения научных и практических задач. Математическая статистика тесно примыкает к теории вероятностей и базируется на ее понятиях. Однако главным в математической статистике является не распределение случайных величин, а анализ статистических данных и выяснение, какому распределению они соответствуют. Большая статистическая совокупность, из которой отбирается часть объектов для исследования, называется генеральной совокупностью , а множество объектов, собранных из нее, – выборочной совокупностью, или выборкой. Статистическое распределение – это совокупность вариант и соответствующих им частот (или относительных частот).
Выборочное наблюдение – это такой вид несплошного наблюдения, при котором из всей изучаемой совокупности случайно, наудачу (путем жеребьевки или другим методом) отбирается определенное число единиц (выборочная совокупность). Для них регистрируются интересующие исследователя признаки, на основании которых исчисляются искомые выборочные показатели (средние величины, относительные и пр.), распространяемые затем на исходную генеральную совокупность [112].
2) оценки генеральной совокупности людей из какой-то особой популяции, которые ведут себя каким-то определенным образом;
Основное преимущество методик с использованием официальной статистики – работа с генеральной совокупностью .
Генеральная совокупность - множество всех объектов, относительно которых предполагается делать выводы при изучении конкретной задачи.
Выборка - часть генеральной совокупности, которая охватывается экспериментом.
Репрезентативная выборка - выборка, в которой все основные признаки генеральной совокупности, из которой извлечена данная выборка, представлены приблизительно в той же пропорции или с той же частотой, с которой данный признак выступает в этой генеральной совокупности.
Унимодальное распределение - распределение, имеющее только одну моду (пример: нормальное распределение)

Способы формирования репрезентативной выборки:
Простая случайная выборка (simple random sample)
Стратифицированная выборка (stratified sample)
Групповая выборка (cluster sample)
Типы переменных:
непрерывные (рост в мм)
дискретные (количество публикаций у учёного)
Ранговые (успеваемость студентов)
Гистограмма частот:
Позволяет сделать первое впечатление о форме распределения некоторого количественного признака.

Описательные статистики:
Меры центральной тенденции (узкий диапазон, высокие значения признака):
Мода (mode) - значение во множестве наблюдений, которое встречается наиболее часто.
Медиана (median) - значение признака, которое делит упорядоченное множество пополам.
Среднее значение (mean, среднее арифметическое) - сумма всех значений измеренного признака, делённая на количество измеренных значений.
( используется для среднего значения из выборки, а для генеральной совокупности латинская буква )
Свойства среднего:
Если к каждому значению выборки прибавить определённое число, то и среднее значение увеличится на это число.
Если каждое значение выборки умножить на определённое число, то и среднее значение увеличится в это число раз.
Если для каждого значения выборки, рассчитать такой показатель как его отклонение от среднего арифметического, то сумма этих отклонений будет равняться нулю.
Меры изменчивости (широкий диапазон, вариативность признака):
Размах (range) - разность максимального и минимального значения.
При добавлении сильно отличающегося значения данные меняются сильно и могут быть некорректные.
Дисперсия (variance) - средний квадрат отклонений индивидуальных значений признака от их средней величины.
Дисперсия генеральной совокупности:
(среднеквадратическое отклонение генеральной совокупности)
(среднеквадратическое отклонение выборки)
Свойства дисперсии:
Квартили распределения и график box-plot
Квартили - три точки (значения признака), которые делят упорядоченное множество данных на четыре равные части.
Box-plot - такой вид диаграммы в удобной форме показывает медиану (или, если нужно, среднее), нижний и верхний квартили, минимальное и максимальное значение выборки и выбросы.


Нормальное распределение
Отклонения наблюдений от среднего подчиняются определённому вероятностному закону.
Стандартизация
Стандартизация или z-преобразование - преобразование полученных данных в стандартную Z-шкалу (Z-scores) со средним и

Правило "двух" и "трёх" сигм
Центральная предельная теорема
Центральная предельная теорема - класс теорем в теории вероятностей, утверждающих, что сумма большого количества независимых случайных величин имеет распределение близкое к нормальному. Так как многие случайные величины в приложениях являются суммами нескольких случайных факторов, центральные предельные теоремы обосновывают популярность нормального распределения.

Есть признак, распределенный КАК УГОДНО* с некоторым средним и некоторым стандартным отклонением. Тогда, если выбирать из этой совокупности выборки объема n, то их средние тоже будут распределены нормально со средним равным среднему признака в ГС и стандартным отклонением .
Стандартная ошибка среднего - теоретическое стандартное отклонение всех средних выборки размера , извлекаемое из совокупности.
Доверительные интервалы для среднего

Доверительный интервал является показателем точности измерений. Это также показатель того, насколько стабильна полученная величина, то есть насколько близкую величину (к первоначальной величине) вы получите при повторении измерений (эксперимента).
Идея статистического вывода

P-значение (P-value) - величина, используемая при тестировании статистических гипотез. Фактически это вероятность ошибки при отклонении нулевой гипотезы (ошибки первого рода).

2. Сравнение средних
T-распределение
Если число наблюдений невелико и \sigma неизвестно (почти всегда), используется распределение Стьюдента (t-distribution).
Унимодально и симметрично, но: наблюдения с большей вероятностью попадают за пределы от

"Форма" распределения определяется числом степеней свободы ().
С увеличением числа распределение стремится к нормальному.
t-распределение используется не потому что у нас маленькие выборки, а потому что мы не знаем стандартное отклонение в генеральной совокупности.
Сравнение двух средних; t-критерий Стьюдента
Критерий, который позволяет сравнивать средние значения двух выборок между собой, называется t-критерий Стьюдента.
Условия для корректности использования t-критерия Стьюдента:
Две независимые группы
Формула стандартной ошибки среднего:
Формула числа степеней свободы:
Формула t-критерия Стьюдента:
Переход к p-критерию:
Проверка распределения на нормальность, QQ-Plot

Однофакторный дисперсионный анализ
Часто в исследованиях необходимо сравнить несколько групп между собой. В таком случае применятся однофакторный дисперсионный анализ.
Незвисимая переменная - номинативная перменная с нескольким градациями, разделяющая наблюдения на группы.
Зависимая перемнная - количественная переменная, по степени выраженности которой сравниваются группы.
Читайте также: