
Модели статистического прогнозирования конспект
Обновлено: 05.07.2024
Обычно в работах как отечественных, так и англоязычных авторы не задаются вопросом классификации методов и моделей прогнозирования, а просто их перечисляют. Но мне кажется, что на сегодняшний день данная область так разрослась и расширилась, что пусть самая общая, но классификация необходима. Ниже представлен мой собственный вариант общей классификации.
В чем разница между методом и моделью прогнозирования?
Метод прогнозирования представляет собой последовательность действий, которые нужно совершить для получения модели прогнозирования. По аналогии с кулинарией метод есть последовательность действий, согласно которой готовится блюдо — то есть сделается прогноз.
Модель прогнозирования есть функциональное представление, адекватно описывающее исследуемый процесс и являющееся основой для получения его будущих значений. В той же кулинарной аналогии модель есть список ингредиентов и их соотношение, необходимый для нашего блюда — прогноза.
Совокупность метода и модели образуют полный рецепт!
В настоящее время принято использовать английские аббревиатуры названий как моделей, так и методов. Например, существует знаменитая модель прогнозирования авторегрессия проинтегрированного скользящего среднего с учетом внешнего фактора (auto regression integrated moving average extended, ARIMAX). Эту модель и соответствующий ей метод обычно называют ARIMAX, а иногда моделью (методом) Бокса-Дженкинса по имени авторов.
Сначала классифицируем методы

Если мы вспомним нашу кулинарную аналогию, то и там можно разделить все рецепты на формализованные, то есть записанные по количеству ингредиентов и способу приготовления, и интуитивные, то есть нигде не записанные и получаемые из опыта кулинара. Когда мы не пользуемся рецептом? Когда блюдо очень просто: пожарить картошку или сварить пельмени — тут рецепт не нужен. Когда еще мы не пользуемся рецептом? Когда желаем изобрести что-то новенькое!
Интуитивные методы прогнозирования имеют дело с суждениями и оценками экспертов. На сегодняшний день они часто применяются в маркетинге, экономике, политике, так как система, поведение которой необходимо спрогнозировать, или очень сложна и не поддается математическому описанию, или очень проста и в таком описании не нуждается. Подробности о такого рода методах можно глянуть в [2].
Формализованные методы — описанные в литературе методы прогнозирования, в результате которых строят модели прогнозирования, то есть определяют такую математическую зависимость, которая позволяет вычислить будущее значение процесса, то есть сделать прогноз.
На этом общая классификация методов прогнозирования на мой взгляд может быть закончена.
Далее сделаем общую классификация моделей
Здесь необходимо переходить к классификации моделей прогнозирования. На первом этапе модели следует разделить на две группы: модели предметной области и модели временных рядов.

Модели предметной области — такие математические модели прогнозирования, для построения которых используют законы предметной области. Например, модель, на которой делают прогноз погоды, содержит уравнения динамики жидкостей и термодинамики. Прогноз развития популяции делается на модели, построенной на дифференциальном уравнении. Прогноз уровня сахара крови человека, больного диабетом, делается на основании системы дифференциальных уравнений. Словом, в таких моделях используются зависимости, свойственные конкретной предметной области. Такого рода моделям свойственен индивидуальный подход в разработке.
Модели временных рядов — математические модели прогнозирования, которые стремятся найти зависимость будущего значения от прошлого внутри самого процесса и на этой зависимости вычислить прогноз. Эти модели универсальны для различных предметных областей, то есть их общий вид не меняется в зависимости от природы временного ряда. Мы можем использовать нейронные сети для прогнозирования температуры воздуха, а после аналогичную модель на нейронных сетях применить для прогноза биржевых индексов. Это обобщенные модели, как кипяток, в которые если бросить продукт, то он сварится вне зависимости от его природы.
Классифицируем модели временных рядов
Мне кажется, что составить общую классификацию моделей предметной области не представляется возможным: сколько областей, столько и моделей! Однако модели временных рядов легко поддаются простому делению [3]. Модели временных рядов можно разделить на две группы: статистические и структурные.

- регрессионные модели (линейная регрессия, нелинейная регрессия);
- авторегрессионные модели (ARIMAX, GARCH, ARDLM);
- модель экспоненциального сглаживания;
- модель по выборке максимального подобия;
- и т.д.
- нейросетевые модели;
- модели на базе цепей Маркова;
- модели на базе классификационно-регрессионных деревьев;
- и т.д.
Для обоих групп я указала основные, то есть наиболее распространенные и подробно описанные модели прогнозирования. Однако на сегодняшний день моделей прогнозирования временных рядов имеется уже громадное количество и для построения прогнозов, например, стали использовать SVM (support vector machine) модели, GA (genetic algorithm) модели и многие другие.
Общая классификация
Таким образом мы получили следующую классификацию моделей и методов прогнозирования.

- Тихонов Э.Е. Прогнозирование в условиях рынка. Невинномысск, 2006. 221 с.
- Armstrong J.S. Forecasting for Marketing // Quantitative Methods in Marketing. London: International Thompson Business Press, 1999. P. 92 – 119.
- Jingfei Yang M. Sc. Power System Short-term Load Forecasting: Thesis for Ph.d degree. Germany, Darmstadt, Elektrotechnik und Informationstechnik der Technischen Universitat, 2006. 139 p.
UPD. 15.11.2016.
Господа, дошло до маразма! Недавно мне прислали на рецензию статью для ВАКовского издания со ссылкой на эту запись. Обращаю внимание, что ни в дипломах, ни в статьях, ни тем более в диссертациях ссылаться на блог нельзя! Если хотите ссылку, то используйте эту: Чучуева И.А. МОДЕЛЬ ПРОГНОЗИРОВАНИЯ ВРЕМЕННЫХ РЯДОВ ПО ВЫБОРКЕ МАКСИМАЛЬНОГО ПОДОБИЯ, диссертация… канд. тех. наук / Московский государственный технический университет им. Н.Э. Баумана. Москва, 2012.
изучит ь несколько новых фу нкций Excel( СУММ, п оиск решений ).
Воспитательная: Убедит ь учащихся в познаваемости мира и объ ективности н аших знаний
Развивающая: Об ъяснить у чащимся плюсы стат истических моделей, показать каков на
практике метод наименьших квадратов, и каким образом переносить созданные на бумаге модели
Оборудование: ноу тбуки у учеников и интерактив ная доска у учителя.
Сегодня мы бу дем изучать Мод ели статистическ ого прогнозировани я .
Для начала откроем у чебники н а странице 197 . Это заданный н а дом параг раф, с которым вы у же
ознакомились. На рису нке 6.2 прив едён график з ависимости заболевши х астмой от концентрации
угарного газа в атмос фере. Нашей за дачей бу дет найти наиболее у дачную фу нкцию,
описывающую при ведённу ю зависимость с помощ ью MS Excel.
Сразу отметим тот факт, что наша мо дель статисти ческая, то есть изобилу ет приближёнными ,
усреднёнными и до статочно неточ ными значениям и, суть т акой модели не в точном подсчёте , а в
прогнозировании тенд енций и приблизит ельных значений. П о этому и подбирать мы бу дем не ту
функцию, которая п ройдёт ч ерез абсолютно в се узловые точки и по дойдёт точ ь - в - точь , а наиболее
простую функци ю отражающую о бщий характ ер и проходящу ю как можно более близко к
В параграфу у же говорилось о том, каким образом можно подобрать таку ю фу нкцию методом
МНК (метод наимень ших квадратов ). Теперь неско лько слов об этапа х подбора такой фу нкции.
1ый этап заключает ся в подборе ви да функции. С овершается это по большому счёту ин туитивно,
2ый этап заключает ся в подборе парам етров функц ии. То есть вычислении её коэффициен тов.
Есть то нам и пона добится метод наимень ших квад ратов. Суть э того метода в том , что сумма
квадратов отклонений и значальног о графика функции от того, чт о мы ищем должна быть

Урок начинается с того, что учащиеся делают прогноз по уже построенной статистической модели. Из урока можно узнать, что называется восстановлением значения и для чего используется экстраполяция.
В данный момент вы не можете посмотреть или раздать видеоурок ученикам
Чтобы получить доступ к этому и другим видеоурокам комплекта, вам нужно добавить его в личный кабинет, приобретя в каталоге.
Получите невероятные возможности



Конспект урока "Моделирование статистического прогнозирования. Прогнозирование по регрессионной модели"
На сегодняшнем уроке мы с вами будем учиться прогнозировать по построенной статистической модели. А также выясним, что называется восстановлением значения и для чего используется экстраполяция.
Но прежде, чем приступить к изучению нового материала, давайте повторим некоторые важные моменты нашего прошлого урока.
На прошлом занятии мы с вами говорили о моделировании статистического прогнозирования и научились получать математическую модель по медицинским статистическим данным.
Для того чтобы получить формулу мы сначала по данным, полученным математическими статистами построили диаграмму. Затем подбирали к диаграмме вид функции. Для этого мы рассматривали стандартные функции.
Как вы помните, Полученную таким образом функцию в статистике называют регрессионной моделью.
То есть регрессионная модель – это функция, описывающая зависимость между количественными характеристиками сложных систем.
Затем, после выбора подходящих функций мы подбирали коэффициенты для них. Причём так, чтобы полученный график функции располагался как можно ближе к экспериментальным точкам. Здесь мы применяли метод наименьших квадратов.
По данному методу искомая функция должна быть построена так, чтобы сумма квадратов отклонений игрек-координат всех экспериментальных точек от игрек-координат графика функции была минимальной.
И, таким образом, получили график регрессионной модели, который называется трендом.
В статистике используется величина Эр в квадрате, которая называется коэффициентом детерминированности, он показывает, насколько удачной является полученная регрессионная модель.
Но для чего мы выполняли все эти построения и вычисления? Для чего нужны такие модели? Ответ на эти и другие вопросы мы получим сегодня на уроке.
Итак, мы получили регрессионную математическую модель по медицинским статистическим данным.
Как вы помните, модель — это объект-заменитель, который в определённых условиях может заменять объект-оригинал. Модель воспроизводит интересующие нас свойства и характеристики оригинала.
То есть наша модель воспроизводит интересующие нас свойства и характеристики, иначе говоря, теперь мы можем прогнозировать процесс путём вычислений.
По данной модели мы можем оценить уровень заболеваемости астмой не только для тех значений концентрации угарного газа, которые были получены экспериментально, но и для других значений.
Построение таких моделей очень важно с практической точки зрения. Если, например, в одном из городов планируется строительство тепловой электростанции, которая является основным источником загрязнения атмосферы, то можно рассчитать вероятную концентрацию угарного газа в воздухе и, соответственно, сделать прогноз на то, как это строительство отразится на здоровье людей.
Есть два способа прогнозирования по регрессионной модели.
Первый способ - восстановление значения.
Если прогноз рассчитывается в пределах экспериментальных значений независимой переменной (у нас независимая переменная – это концентрация угарного газа C), то такой прогноз называется восстановлением значения.
Второй способ - экстраполяция.
Если прогноз рассчитывается за пределами экспериментальных данных. Такой прогноз называется экстраполяцией.
Регрессионную модель просто строить, а затем прогнозировать по ней, с помощью электронных таблиц, например, Microsoft Excel.
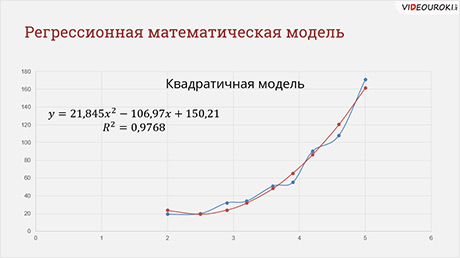
На прошлом уроке мы выяснили, что наиболее подходящей является квадратичная зависимость.
Давайте построим электронную таблицу прогнозирования по регрессионной модели первым способом, то есть восстановление значения. Значения независимой переменной будем брать в пределах экспериментальных значений, в нашем случает от двух до пяти.
Итак, в ячейку А1 введём - Концентрация угарного газа (миллиграмм на метр кубический), в ячейку Б1 - Число больных астмой на одну тысячу жителей.
В ячейку А2 будем вводить значения концентрации угарного газа в промежутке от двух до пяти.
В ячейку Б2 вводим формулу для расчёта числа больных астмой на тысячу жителей. Итак, на прошлом уроке мы получили математическую формулу модели: игрек равно 21 целая 845 тысячных икс в квадрате минус 106 целых 97 сотых икс плюс 150 целых 21 сотая.
Протестируем нашу модель. Введём в ячейку А2 значение концентрации угарного газа равное трём. В ячейке Б2 отобразится результат вычислений. Число больных астмой будет равно двадцати пяти целым девятистам пяти тысячным жителя.
Однако считать число людей, даже среднее в дробных величинах нет смысла. Поэтому, нажимаем правой кнопкой мыши на ячейку Б2 и в раскрывшемся меню выберем формат ячеек. В раскрывшемся меню выберем числовые форматы – числовой и в окошке число десятичных знаков, поставим ноль.
Теперь число больных астмой будет равно 26 жителей.
Прогнозирование вторым способом – экстраполяционным производится подобным образом.
Введём в ячейку А2 значение концентрации угарного газа равное шести. В ячейке Б2 отобразится результат - 295 жителей.
Также с помощью табличного процессора Excel можно выполнять экстраполяцию графически. Для этого нужно продолжить тренд, или график регрессионной модели, за пределы экспериментальных данных.
Но бывают случаи, когда экстраполяция может оказаться неправдивой.
Применение всякой регрессионной модели ограничено, особенно за пределами экспериментальной области. В нашем примере при экстраполяции не следует далеко уходить от величины 5 миллиграмм на метр кубический.
Квадратичная модель в данном примере в области малых значений концентрации, близких к 0, вообще не годится.
Ведём в нашу таблицу значение концентрации угарного газа 0, получим 150 человек больных астмой, т. е. больше, чем при четырёх миллиграммах на метр кубический. Конечно, это неправда. В области малых значений С лучше работает экспоненциальная модель. Кстати, это довольно типичная ситуация: разным областям данных могут лучше соответствовать разные модели.
А теперь давайте вспомним всё, что мы сегодня изучили на уроке.
По полученной регрессионной модели можно прогнозировать процесс путём вычислений.
Есть два способа прогнозирования по регрессионной модели.
Первый способ. Если прогноз рассчитывается в пределах экспериментальных значений независимой переменной. Такой прогноз называется восстановлением значения.
Второй способ. Если прогноз рассчитывается за пределами экспериментальных данных. Такой прогноз называется экстраполяцией.
Регрессионную модель просто строить, а затем прогнозировать по ней, с помощью электронных таблиц.
Внимание Скидка 50% на курсы! Спешите подать
заявку
Профессиональной переподготовки 30 курсов от 6900 руб.
Курсы для всех от 3000 руб. от 1500 руб.
Повышение квалификации 36 курсов от 1500 руб.
Лицензия №037267 от 17.03.2016 г.
выдана департаментом образования г. Москвы

Конспект урока по Информатике "Модели Статистического прогнозирования" 11 класс
Учитель информатики: Клименко С.И. МОУСОШ№87 г. Волгоград
Дидактическая: Выяснить особенности статистических моделей, вспомнить обобщённую формулу квадратичной функции, ознакомиться с методом наименьших квадратов, изучить несколько новых функций Excel (СУММ, поиск решений).
Воспитательная: Убедить учащихся в познаваемости мира и объективности наших знаний о нем.
Развивающая: Объяснить учащимся плюсы статистических моделей, показать каков на практике метод наименьших квадратов, и каким образом переносить созданные на бумаге модели в Excel .
Тип урока: изложение нового материала.
Вид урока: беседа, решение задач.
Оборудование: ноутбуки у учеников и интерактивная доска у учителя.
Изложение нового материала
Постановка и поэтапное решение задачи в теоретическом виде.
Последующая адаптация алгоритма решения под MS Excel .
Следят за ходом мысли учителя , по возможности принимая участие в процессе решения, делают выводы и записывают их в тетрадь
Пытаются самостоятельно перенести алгоритм решения задачи в MS Excel .
Сегодня мы будем изучать Модели статистического прогнозирования .
Для начала откроем учебники на странице 197 .Это заданный на дом параграф, с которым вы уже ознакомились. На рисунке 6.2 приведён график зависимости заболевших астмой от концентрации угарного газа в атмосфере. Нашей задачей будет найти наиболее удачную функцию, описывающую приведённую зависимость с помощью MS Excel .
Сразу отметим тот факт, что наша модель статистическая, то есть изобилует приближёнными, усреднёнными и достаточно неточными значениями, суть такой модели не в точном подсчёте , а в прогнозировании тенденций и приблизительных значений. По этому и подбирать мы будем не ту функцию, которая пройдёт через абсолютно все узловые точки и подойдёт точь-в-точь , а наиболее простую функцию отражающую общий характер и проходящую как можно более близко к графику приведённому на рисунке.
В параграфу уже говорилось о том, каким образом можно подобрать такую функцию методом МНК (метод наименьших квадратов). Теперь несколько слов об этапах подбора такой функции.
1ый этап заключается в подборе вида функции. Совершается это по большому счёту интуитивно, методом перебора вариантов.
2ый этап заключается в подборе параметров функции. То есть вычислении её коэффициентов.
Есть то нам и понадобится метод наименьших квадратов. Суть этого метода в том, что сумма квадратов отклонений изначального графика функции от того, что мы ищем должна быть минимальна.
Теперь следует непосредственно открыть Excel и переписать туда таблицу приведённую на рисунке 6.2
Вы полня первый этап мы понимаем что наша функция по виду напоминает квадратичную. Её общий вид таков :
Значит на втором этапе мы будем искать 3 коэффициента: a , b , c .
Искать их мы будем методом МНК.
Выберем три колонки, в которых буду располагаться наши коэффициенты. Сначала впишем в них произвольные значения. Пусть это будут a =1, b =2, c =4.
Далее прописываем колонку с значениями квадратов отклонений. В ячейку впишем =(ячейка с P 1-ячейка со значением P при таком же значении концентрации угарного газа( C ))^2.
Распространяем эту формулу на все ячейки.
Задача решена. Для наглядности имеет смысл самостоятельно построить график с исходной и подобранной нами функций и увидеть как они соотносятся.
Плюсом таким моделей является то, что мы можем предсказывать развитие ситуацию проводя анализ более ранних её форм. Не прибегая к непосредственным опытам.
Читайте также: