
Основные элементы базы данных кратко
Обновлено: 03.07.2024
ИНФОРМАТИКА- НАУКА, ИЗУЧАЮЩАЯ СПОСОБЫ АВТОМАТИЗИРОВАННОГО СОЗДАНИЯ, ХРАНЕНИЯ, ОБРАБОТКИ, ИСПОЛЬЗОВАНИЯ, ПЕРЕДАЧИ И ЗАЩИТЫ ИНФОРМАЦИИ.
ИНФОРМАЦИЯ – ЭТО НАБОР СИМВОЛОВ, ГРАФИЧЕСКИХ ОБРАЗОВ ИЛИ ЗВУКОВЫХ СИГНАЛОВ, НЕСУЩИХ ОПРЕДЕЛЕННУЮ СМЫСЛОВУЮ НАГРУЗКУ.
ЭЛЕКТРОННО-ВЫЧИСЛИТЕЛЬНАЯ МАШИНА (ЭВМ) ИЛИ КОМПЬЮТЕР (англ. computer- -вычислитель)-УСТРОЙСТВО ДЛЯ АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ ИНФОРМАЦИИ. Принципиальное отличие использования ЭВМ от всех других способов обработки информации заключается в способности выполнения определенных операций без непосредственного участия человека, но по заранее составленной им программе. Информация в современном мире приравнивается по своему значению для развития общества или страны к важнейшим ресурсам наряду с сырьем и энергией. Еще в 1971 году президент Академии наук США Ф.Хандлер говорил: "Наша экономика основана не на естественных ресурсах, а на умах и применении научного знания".
В развитых странах большинство работающих заняты не в сфере производства, а в той или иной степени занимаются обработкой информации. Поэтому философы называют нашу эпоху постиндустриальной. В 1983 году американский сенатор Г.Харт охарактеризовал этот процесс так: "Мы переходим от экономики, основанной на тяжелой промышленности, к экономике, которая все больше ориентируется на информацию, новейшую технику и технологию, средства связи и услуги.."
2. КРАТКАЯ ИСТОРИЯ РАЗВИТИЯ ВЫЧИСЛИТЕЛЬНОЙ ТЕХНИКИ.
Вся история развития человеческого общества связана с накоплением и обменом информацией (наскальная живопись, письменность, библиотеки, почта, телефон, радио, счеты и механические арифмометры и др.). Коренной перелом в области технологии обработки информации начался после второй мировой войны.
В вычислительных машинах первого поколения основными элементами были электронные лампы. Эти машины занимали громадные залы, весили сотни тонн и расходовали сотни киловатт электроэнергии. Их быстродействие и надежность были низкими, а стоимость достигала 500-700 тысяч долларов.
Появление более мощных и дешевых ЭВМ второго поколения стало возможным благодаря изобретению в 1948 году полупроводниковых устройств- транзисторов. Главный недостаток машин первого и второго поколений заключался в том, что они собирались из большого числа компонент, соединяемых между собой. Точки соединения (пайки) являются самыми ненадежными местами в электронной технике, поэтому эти ЭВМ часто выходили из строя.
В ЭВМ третьего поколения (с середины 60-х годов ХХ века) стали использоваться интегральные микросхемы (чипы)- устройства, содержащие в себе тысячи транзисторов и других элементов, но изготовляемые как единое целое, без сварных или паяных соединений этих элементов между собой. Это привело не только к резкому увеличению надежности ЭВМ, но и к снижению размеров, энергопотребления и стоимости (до 50 тысяч долларов).
История ЭВМ четвертого поколения началась в 1970 году, когда ранее никому не известная американская фирма INTEL создала большую интегральную схему (БИС), содержащую в себе практически всю основную электронику компьютера. Цена одной такой схемы (микропроцессора) составляла всего несколько десятков долларов, что в итоге и привело к снижению цен на ЭВМ до уровня доступных широкому кругу пользователей.
СОВРЕМЕННЫЕ КОМПЬТЕРЫ- ЭТО ЭВМ ЧЕТВЕРТОГО ПОКОЛЕНИЯ, В КОТОРЫХ ИСПОЛЬЗУЮТСЯ БОЛЬШИЕ ИНТЕГРАЛЬНЫЕ СХЕМЫ.
90-ые годы ХХ-го века ознаменовались бурным развитием компьютерных сетей, охватывающих весь мир. Именно к началу 90-ых количество подключенных к ним компьютеров достигло такого большого значения, что объем ресурсов доступных пользователям сетей привел к переходу ЭВМ в новое качество. Компьютеры стали инструментом для принципиально нового способа общения людей через сети, обеспечивающего практически неограниченный доступ к информации, находящейся на огромном множестве компьюторов во всем мире - "глобальной информационной среде обитания".
6.ПРЕДСТАВЛЕНИЕ ИНФОРМАЦИИ В КОМПЬЮТЕРЕ И ЕЕ ОБЪЕМ.
ЭТО СВЯЗАНО С ТЕМ, ЧТО ИНФОРМАЦИЮ, ПРЕДСТАВЛЕННУЮ В ТАКОМ ВИДЕ, ЛЕГКО ТЕХНИЧЕСКИ СМОДЕЛИРОВАТЬ, НАПРИМЕР, В ВИДЕ ЭЛЕКТРИЧЕСКИХ СИГНАЛОВ. Если в какой-то момент времени по проводнику идет ток, то по нему передается единица, если тока нет- ноль. Аналогично, если направление магнитного поля на каком-то участке поверхности магнитного диска одно- на этом участке записан ноль, другое- единица. Если определенный участок поверхности оптического диска отражает лазерный луч- на нем записан ноль, не отражает- единица.
ОБЪЕМ ИНФОРМАЦИИ, НЕОБХОДИМЫЙ ДЛЯ ЗАПОМИНАНИЯ ОДНОГО ИЗ ДВУХ СИМВОЛОВ-0 ИЛИ 1, НАЗЫВАЕТСЯ 1 БИТ (англ. binary digit- двоичная единица). 1 бит- минимально возможный объем информации. Он соответствует промежутку времени, в течение которого по проводнику передается или не передается электрический сигнал, участку поверхности магнитного диска, частицы которого намагничены в том или другом направлении, участку поверхности оптического диска, который отражает или не отражает лазерный луч, одному триггеру, находящемуся в одном из двух возможных состояний.
Итак, если у нас есть один бит, то с его помощью мы можем закодировать один из двух символов- либо 0, либо 1.
Если же есть 2 бита, то из них можно составить один из четырех вариантов кодов: 00 , 01 , 10 , 11 .
Если есть 3 бита- один из восьми: 000 , 001 , 010 , 100 , 110 , 101 , 011 , 111 .
1 бит- 2 варианта,
2 бита- 4 варианта,
3 бита- 8 вариантов;
Продолжая дальше, получим:
4 бита- 16 вариантов,
5 бит- 32 варианта,
6 бит- 64 варианта,
7 бит- 128 вариантов,
8 бит- 256 вариантов,
9 бит- 512 вариантов,
10 бит- 1024 варианта,
N бит - 2 в степени N вариантов.
В обычной жизни нам достаточно 150-160 стандартных символов (больших и маленьких русских и латинских букв, цифр, знаков препинания, арифметических действий и т.п.). Если каждому из них будет соответствовать свой код из нулей и единиц, то 7 бит для этого будет недостаточно (7 бит позволят закодировать только 128 различных символов), поэтому используют 8 бит.
ДЛЯ КОДИРОВАНИЯ ОДНОГО ПРИВЫЧНОГО ЧЕЛОВЕКУ СИМВОЛА В КОМПЬЮТЕРЕ ИСПОЛЬЗУЕТСЯ 8 БИТ, ЧТО ПОЗВОЛЯЕТ ЗАКОДИРОВАТЬ 256 РАЗЛИЧНЫХ СИМВОЛОВ.
СТАНДАРТНЫЙ НАБОР ИЗ 256 СИМВОЛОВ НАЗЫВАЕТСЯ ASCII ( произносится "аски", означает "Американский Стандартный Код для Обмена Информацией"- англ. American Standart Code for Information Interchange).
ОН ВКЛЮЧАЕТ В СЕБЯ БОЛЬШИЕ И МАЛЕНЬКИЕ РУССКИЕ И ЛАТИНСКИЕ БУКВЫ, ЦИФРЫ, ЗНАКИ ПРЕПИНАНИЯ И АРИФМЕТИЧЕСКИХ ДЕЙСТВИЙ И Т.П.
A - 01000001, B - 01000010, C - 01000011, D - 01000100, и т.д.
Таким образом, если человек создает текстовый файл и записывает его на диск, то на самом деле каждый введенный человеком символ хранится в памяти компьютера в виде набора из восьми нулей и единиц. При выводе этого текста на экран или на бумагу специальные схемы - знакогенераторы видеоадаптера (устройства, управляющего работой дисплея) или принтера образуют в соответствии с этими кодами изображения соответствующих символов.
Набор ASCII был разработан в США Американским Национальным Институтом Стандартов (ANSI), но может быть использован и в других странах, поскольку вторая половина из 256 стандартных символов, т.е. 128 символов, могут быть с помощью специальных программ заменены на другие, в частности на символы национального алфавита, в нашем случае - буквы кириллицы. Поэтому, например, передавать по электронной почте за границу тексты, содержащие русские буквы, бессмысленно. В англоязычных странах на экране дисплея вместо русской буквы Ь будет высвечиваться символ английского фунта стерлинга, вместо буквы р - греческая буква альфа, вместо буквы л - одна вторая и т.д.
ОБЪЕМ ИНФОРМАЦИИ, НЕОБХОДИМЫЙ ДЛЯ ЗАПОМИНАНИЯ ОДНОГО СИМВОЛА ASCII НАЗЫВАЕТСЯ 1 БАЙТ.
Очевидно что, поскольку под один стандартный ASCII-символ отводится 8 бит,
Остальные единицы объема информации являются производными от байта:
1 КИЛОБАЙТ = 1024 БАЙТА И СООТВЕТСТВУЕТ ПРИМЕРНО ПОЛОВИНЕ СТРАНИЦЫ ТЕКСТА,
1 МЕГАБАЙТ = 1024 КИЛОБАЙТАМ И СООТВЕТСТВУЕТ ПРИМЕРНО 500 СТРАНИЦАМ ТЕКСТА,
1 ГИГАБАЙТ = 1024 МЕГАБАЙТАМ И СООТВЕТСТВУЕТ ПРИМЕРНО 2 КОМПЛЕКТАМ ЭНЦИКЛОПЕДИИ,
1 ТЕРАБАЙТ = 1024 ГИГАБАЙТАМ И СООТВЕТСТВУЕТ ПРИМЕРНО 2000 КОМПЛЕКТАМ ЭНЦИКЛОПЕДИИ.
Обратите внимание, что в информатике смысл приставок кило- , мега- и других в общепринятом смысле выполняется не точно, а приближенно, поскольку соответствует увеличению не в 1000, а в 1024 раза.
СКОРОСТЬ ПЕРЕДАЧИ ИНФОРМАЦИИ ПО ЛИНИЯМ СВЯЗИ ИЗМЕРЯЕТСЯ В БОДАХ.
1 БОД = 1 БИТ/СЕК.
В частности, если говорят, что пропускная способность какого-то устройства составляет 28 Килобод, то это значит, что с его помощью можно передать по линии связи около 28 тысяч нулей и единиц за одну секунду.
7. СЖАТИЕ ИНФОРМАЦИИ НА ДИСКЕ
ИНФОРМАЦИЮ НА ДИСКЕ МОЖНО ОБРАБОТАТЬ С ПОМОЩЬЮ СПЕЦИАЛЬНЫХ ПРОГРАММ ТАКИМ ОБРАЗОМ, ЧТОБЫ ОНА ЗАНИМАЛА МЕНЬШИЙ ОБЪЕМ.
Существуют различные методы сжатия информации. Некоторые из них ориентированы на сжатие текстовых файлов, другие - графических, и т.д. Однако во всех них используется общая идея, заключающаяся в замене повторяющихся последовательностей бит более короткими кодами. Например, в романе Л.Н.Толстого "Война и мир" несколько миллионов слов, но большинство из них повторяется не один раз, а некоторые- до нескольких тысяч раз. Если все слова пронумеровать, текст можно хранить в виде последовательности чисел - по одному на слово, причем если повторяются слова, то повторяются и числа. Поэтому, такой текст (особенно очень большой, поскольку в нем чаще будут повторяться одни и те же слова) будет занимать меньше места.
Сжатие информации используют, если объем носителя информации недостаточен для хранения требуемого объема информации или информацию надо послать по электронной почте
Программы, используемые при сжатии отдельных файлов называются архиваторами. Эти программы часто позволяют достичь степени сжатия информации в несколько раз.
База данных (БД) - это поименованная совокупность структурированных данных, относящихся к определенной предметной области и предназначенных для хранения, накопления и обработки с помощью ЭВМ.
Реляционная База Данных (РБД) - это набор отношений, имена которых совпадают с именами схемотношений в схеме БД.
Основные понятия реляционных баз данных:
· Домен (domain) – множество всех допустимых значений атрибута.
· Атрибут (attribute) – заголовок столбца таблицы, характеризующий поименованное свойство объекта, например, фамилия студента, дата оформления заказа, пол сотрудника и т.п.
· Кортеж – строка таблицы, представляющая собой совокупность значений логически связанных атрибутов.
· Отношение (relation) – таблица, отражающая информацию об объектах реального мира, например, о студентах, заказах, сотрудниках, жителях и т.д.
· Первичный ключ (primary key) – поле (или набор полей) таблицы, однозначно идентифицирующий каждую из ее записей.
· Альтернативный ключ – это поле (или набор полей), несовпадающее с первичным ключом и уникально идентифицирующий экземпляр записи.
· Внешний ключ – это поле (или набор полей), чьи значения совпадают с имеющимися значениями первичного ключа другой таблицы. При связи двух таблиц с первичным ключом первой таблицы связывается внешний ключ второй таблицы.
· Реляционная модель данных (РМД)- организация данных в виде двумерных таблиц.
Каждая реляционная таблица должна обладать следующими свойствами:
1. Каждая запись таблицы уникальна, т.е. совокупность значений по полям не повторяется.
2. Каждое значение, записывается на пересечении строки и столбца - является атомарным (неразделимым).
3. Значения каждого поля должны быть одного типа.
4. Каждое поле имеет уникальное имя.
5. Порядок расположения записей несущественен.
Основные элементы БД:
Поле - элементарная единица логической организации данных. Для описания поля используются следующие характеристики:
· имя, например, Фамилия, Имя, Отчество, Дата рождения;
· тип, например, строковый, символьный, числовой, датовый;
· длина, например, в байтах;
· точность для числовых данных, например, два десятичных знака для отображения дробной части числа.
Запись - совокупность значений логически связанных полей.
Индекс – средство ускорения операции поиска записей, использующееся для установки связей между таблицами. Таблица, для которой используется индекс, называют индексированной. При работе с индексами необходимо обращать внимание на организацию индексов, являющуюся основой для классификации. Простой индекс представлен одним полем или логическим выражением, обрабатывающим одно поле. Составной индекс представлен несколькими полями с возможностью использования различных функций. Индексы таблицы хранятся в индексном файле.
Целостность данных – это средство защиты данных по полям связи, позволяющее поддерживать таблицы в согласованном (непротиворечивом) состоянии (то есть не допускающее существование в подчиненной таблице записей, не имеющих соответствующих записей в родительской таблице).
Запрос – сформулированный вопрос к одной или нескольким взаимосвязанным таблицам, содержащий критерии выборки данных. Запрос осуществляется с помощью структурированного языка запросов SQL (Srtructured Query Language). В результате выборки данных из одной или нескольких таблиц может быть получено множество записей, называемое представлением.
Представление данных – сохраняемый в базе данных именованный запрос на выборку данных (из одной или нескольких таблиц).
Представление, по существу, является временной таблицей, формируемой в результате выполнения запроса. Сам запрос может быть направлен в отдельный файл, отчет, временную таблицу, таблицу на диске и т.п.
Отчет – компонент системы, основное назначение которого – описание и вывод на печать документов на основе информации из БД.
Общая характеристика работы с РБД:
Наиболее распространенная трактовка реляционной модели данных, по-видимому, принадлежит Дейту, который воспроизводит ее (с различными уточнениями) практически во всех своих книгах. Согласно Дейту реляционная модель состоит из трех частей, описывающих разные аспекты реляционного подхода: структурной части, манипуляционной части и целостной части.
В структурной части модели фиксируется, что единственной структурой данных, используемой в реляционных БД, является нормализованное n-арное отношение.
В манипуляционной части модели утверждаются два фундаментальных механизма манипулирования реляционными БД - реляционная алгебра и реляционное исчисление. Первый механизм базируется в основном на классической теории множеств (с некоторыми уточнениями), а второй - на классическом логическом аппарате исчисления предикатов первого порядка. Заметим, что основной функцией манипуляционной части реляционной модели является обеспечение меры реляционности любого конкретного языка реляционных БД: язык называется реляционным, если он обладает не меньшей выразительностью и мощностью, чем реляционная алгебра или реляционное исчисление.
28. АЛГОРИТМИЧЕСКИЕ ЯЗЫКИ. ТРАНСЛЯТОРЫ (ИНТЕРПРЕТАТОРЫ И КОМПИЛЯТОРЫ). АЛГОРИТМИЧЕСКИЙ ЯЗЫК БЕЙСИК. СТРУКТУРА ПРОГРАММЫ. ИДЕНТИФИКАТОРЫ. ПЕРЕМЕННЫЕ. ОПЕРАТОРЫ. ОБРАБОТКА ОДНОМЕРНЫХ И ДВУХМЕРНЫХ МАССИВОВ. ФУНКЦИИ ПОЛЬЗОВАТЕЛЯ. ПОДПРОГРАММЫ. РАБОТА С ФАЙЛАМИ ДАННЫХ.[15]
Язык высокого уровня - язык программирования, понятия и структура которого удобны для восприятия человеком.
Алгоритмический язык (Algorithmic language) - язык программирования - искусственный (формальный) язык, предназначенный для записи алгоритмов. Язык программирования задается своим описанием и реализуется в виде специальной программы: компилятора или интерпретатора. Примерами алгоритмических языков служат – Borland Pascal, C++, Basic и т.д.
Основные понятия алгоритмического языка:
Состав языка:
Обычный разговорный язык состоит из четырех основных элементов: символов, слов, словосочетаний и предложений. Алгоритмический язык содержит подобные элементы, только слова называют элементарными конструкциями, словосочетания - выражениями, предложения - операторами.
Символы , элементарные конструкции, выражения и операторы составляют иерархическую структуру, поскольку элементарные конструкции образуются из последовательности символов.
Выражения - это последовательность элементарных конструкций и символов,
Оператор - последовательность выражений, элементарных конструкций и символов.
Описание языка:
Описание символов заключается в перечислении допустимых символов языка. Под описанием элементарных конструкций понимают правила их образования. Описание выражений - это правила образования любых выражений, имеющих смысл в данном языке. Описание операторов состоит из рассмотрения всех типов операторов, допустимых в языке. Описание каждого элемента языка задается его СИНТАКСИСОМ и СЕМАНТИКОЙ.
Синтаксические определения устанавливают правила построения элементов языка.
Семантика определяет смысл и правила использования тех элементов языка, для которых были даны синтаксические определения.
Символы языка - это основные неделимые знаки, в терминах которых пишутся все тексты на языке.
Элементарные конструкции - это минимальные единицы языка, имеющие самостоятельный смысл. Они образуются из основных символов языка.
Выражение в алгоритмическом языке состоит из элементарных конструкций и символов, оно задает правило вычисления некоторого значения.
Оператор задает полное описание некоторого действия, которое необходимо выполнить. Для описания сложного действия может потребоваться группа операторов.
В этом случае операторы объединяются в Составной оператор или Блок. Действия , заданные операторами, выполняются над данными. Предложения алгоритмического языка, в которых даются сведения о типах данных, называются описаниями или неисполняемыми операторами. Объединенная единым алгоритмом совокупность описаний и операторов образует программу на алгоритмическом языке. В процессе изучения алгоритмического языка необходимо отличать алгоритмический язык от того языка, с помощью которого осуществляется описание изучаемого алгоритмического языка. Обычно изучаемый язык называют просто языком, а язык, в терминах которого дается описание изучаемого языка - Метаязыком.
Трансляторы - (англ. translator — переводчик) — это программа-переводчик. Она преобразует программу, написанную на одном из языков высокого уровня, в программу, состоящую из машинных команд.
Программа, написанная на каком-либо алгоритмическом языке высокого уровня, не может быть непосредственно выполнена на ЭВМ. ЭВМ понимает только язык машинных команд. Следовательно, программа на алгоритмическом языке должна быть переведена (транслирована) на язык команд конкретной ЭВМ. Такой перевод осуществляется автоматически специальными программами-трансляторами, создаваемыми для каждого алгоритмического языка и для каждого типа компьютеров.
Существуют два основных способа трансляции — компиляция и интерпретация.
1. Компиляция: Компилятор (англ. compiler — составитель, собиратель) читает всю программу целиком, делает ее перевод и создает законченный вариант программы на машинном языке, который затем и выполняется.
При компиляции вся исходная программа сразу превращается в последовательность машинных команд. После этого полученная результирующая программа выполняется ЭВМ с имеющимися исходными данными. Достоинство такого способа состоит в том, что трансляция выполняется один раз, а (многократное) выполнение результирующей программы может осуществляться с большой скоростью. Вместе с тем результирующая программа может занять в памяти ЭВМ очень много места, так как один оператор языка при трансляции заменяется сотнями или даже тысячами команд. Кроме того, отладка и видоизменения транслированной программы весьма затруднены.
2. Интерпретация: Интерпретатор (англ. interpreter — истолкователь, устный переводчик) переводит и выполняет программу строка за строкой.
При интерпретации исходная программа хранится в памяти ЭВМ почти в неизменном виде. Программа-интерпретатор декодирует операторы исходной программы по одному и тут же обеспечивает их выполнение с имеющимися данными. Интерпретируемая программа занимает в памяти компьютера мало места, ее легко отлаживать и видоизменять. Зато выполнение программы происходит достаточно медленно, поскольку при каждом исполнении заново осуществляется поочередная интерпретация всех операторов.
Откомпилированные программы работают быстрее, но интерпретируемые проще исправлять и изменять
Каждый конкретный язык ориентирован либо на компиляцию, либо на интерпретацию — в зависимости от того, для каких целей он создавался. Например, Паскаль обычно используется для решения довольно сложных задач, в которых важна скорость работы программ. Поэтому данный язык обычно реализуется с помощью компилятора.
С другой стороны, Бейсик создавался как язык для начинающих программистов, для которых построчное выполнение программы имеет неоспоримые преимущества.
Иногда для одного языка имеется и компилятор, и интерпретатор. В этом случае для разработки и тестирования программы можно воспользоваться интерпретатором, а затем откомпилировать отлаженную программу, чтобы повысить скорость ее выполнения.
Понятие базы данных тесно связано с такими понятиями структурных элементов, как поле, запись, файл (таблица).
Поле — элементарная единица логической организации данных, которая соответствует неделимой единице информации —реквизиту. Для описания поля используются следующие характеристики:
имя, например, Фамилия, Имя, Отчество, Дата рождения;
тип, например, символьный, числовой, календарный;
длина, например, 15 байт, причем будет определяться максимально возможным количеством символов;
точность для числовых данных, например два десятичных знака для отображения дробной части числа.
· Запись —совокупность логически связанных полей.Экземпляр записи — отдельная реализация записи, содержащая конкретные значения ее полей.
· Файл (таблица) —совокупность экземпляров записей одной структуры.
Описание логической структуры записи файла содержит последовательность расположения полей записи и их основные характеристики.
В структуре записи файла указываются поля, значения которых являются ключами:
первичными(ПК), которые идентифицируют экземпляр записи, и вторичными (ВК), которые выполняют роль поисковых или группировочных признаков (по значению вторичного ключа можно найти несколько записей).
Более подробно про Базу Данных читайте тут.
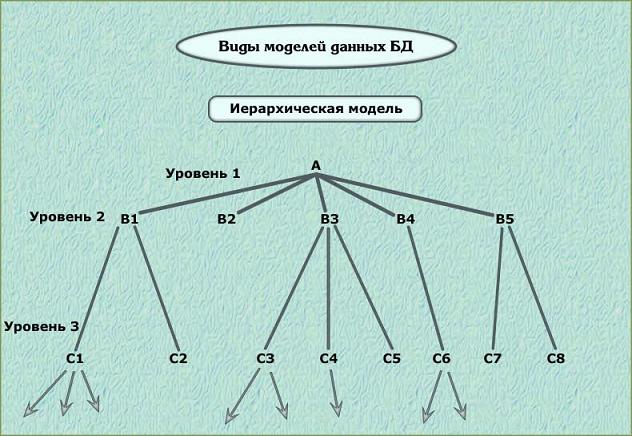
42. Виды моделей данных.
Модель данных - это совокупность структур данных и операций их обработки. Рассмотрим три основных типа моделей данных: иерархическую, сетевую и реляционную.
Виды моделей данных БД. Иерархическая модель
Представляет собой совокупность элементов, расположенных в порядке их подчинения от общего к частному и образующих перевернутое по структуре дерево (граф).
К основным понятиям иерархической структуры относятся уровень, узел и связь. Узел - это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину, не подчиненную никакой другой вершине и находящуюся на самом верхнем - первом уровне. Зависимые (подчиненные) узлы находятся на втором, третьем и т. д. уровнях. Количество деревьев в базе данных определяется числом корневых записей. К каждой записи базы данных существует только один иерархический путь от корневой записи.
Сетевая модель данных
Отличается большой гибкостью, так как в ней существует возможность устанавливать дополнительно к вертикальным иерархическим связям горизонтальные связи. Это облегчает процесс поиска требуемых элементов данных, так как уже не требуется обязательного прохождения всех существующих ступеней.
Сетевой БД фактически является Всемирная паутина глобальной компьютерной сети Интернет. Гиперссылки связывают между собой сотни миллионов документов в единую сетевую БД.

Реляционная модель данных
В реляционной БД под записью понимается строка прямоугольной таблицы. Элементы записи образуют столбцы этой таблицы (поля). Все элементы в столбце имеют одинаковый тип (числовой, символьный), а каждый столбец - неповторяющееся имя. Одинаковые строки в таблице отсутствуют.
43. Типы связей.
Каждому значению первичного ключа в главной таблице соответствует одна или не одной записи в подчиненной таблице.
Каждому значению первичного ключа в главной таблице соответствует одна, несколько или ни одной записи в подчиненной таблице.

44. Построение информационно-логической модели. Архитектура СУБД. Понятие информационно-логической модели.
Важнейшим этапом проектирования базы данных является разработка инфологической (информационно-логической) модели предметной области, не ориентированной на СУБД. В инфологической модели средствами структур данных в интегрированном виде отражают состав и структуру данных, а также информационные потребности приложений (задач и запросов).
Информационно-логическая (инфологическая) модель предметной области отражает предметную область в виде совокупности информационных объектов и их структурных связей.
Инфологическая модель предметной области строится первой. Предварительная инфологическая модель строится еще на предпроектной стадии и затем уточняется на более поздних стадиях проектирования баз данных. Затем на ее основе строятся концептуальная (логическая), внутренняя (физическая) и внешняя модели [5, 6].
На рис. 15.25 представлена графическая форма информационно-логической модели, связывающей информационные объекты: Студент, Сессия, Стипендия, Преподаватель.
Внешний уровень
Это индивидуальный уровень пользователя. Пользователь может быть прикладным программистом или конечным пользователем с любым уровнем профессиональной подготовки. Особое место среди пользователей занимает администратор БД. (В отличие от остальных пользователей его интересует также концептуальный и внутренний уровень.)
У каждого пользователя есть свой язык общения.
Для конечного пользователя это или специальный язык запросов, или язык специального назначения, возможно, основанный на формах и меню, созданный специально с учетом требований и поддерживаемый некоторым оперативным приложением.
Язык обработки данных состоит из таких выполняемых операторов PL/1, которые передают информацию в и из БД; опять же, возможно, включая, новые специальные операторы.
В общем, внешнее представление состоит из множества экземпляров каждого типа внешней записи, которые, в свою очередь, отнюдь не обязательно должны совпадать с ранимыми записями. Находящийся в распоряжении пользователя подъязык данных определен в терминах внешних записей; например, операция выборки языка обработки данных будет проводить выборку из экземпляров внешних, а не хранимых записей.
Концептуальный уровень.
Концептуальное представление состоит из множества экземпляров каждого типа концептуальной записи. Например, оно может состоять из набора экземпляров записей, содержащих информацию об отдельных, плюс набор экземпляров, содержащих информацию о деталях и т.д. Концептуальная запись вовсе не обязательно должна совпадать с внешней записью, с одной стороны, и с хранимой записью- с другой.
Концептуальное представление определяется с помощью концептуальной схемы, которая включает определения каждого типа концептуальных записей.
Концептуальная схема использует другой язык определения данных - концептуальный. Концептуальное представление - это представление всего содержимого базы данных, а концептуальная схема - это определение такого представления. Однако было бы ошибкой полагать, что концептуальная схема - это не более чем набор определений, больше напоминающих простые отношения записей в программе на языке COBOL (или каком-либо другом).
Теперь перейдем к более детальному исследованию трех уровней архитектуры.
Внутренний уровень.
Внутреннее представление описывается с помощью внутренней схемы, которая определяет не только различные типы хранимых записей, но также существующие индексы, способы представления хранимых полей, физическую последовательность хранимых записей и т.д. Внутренняя схема пишется с использованием еще одного языка определения данных - внутреннего.
В заключении отметим, что в некоторых исключительных ситуациях прикладные программы, в частности те, которые называют утилитами могут выполнять операции непосредственно на внутреннем, а не на внешнем уровне. Конечно, такой практикой пользоваться не рекомендуется; она определяет риск с точки зрения безопасности (правила безопасности игнорируются) и целостности (правила целостности тоже игнорируется), к тому же программа будет зависеть от загруженных данных; но иногда это может быть единственным способом достичь выполнения требуемой функции или добиться необходимого быстродействия - так же, как пользователю языка высокого уровня иногда по тем же причинам необходимо прибегнуть к языку ассемблера.
Приложения, использующие базы данных, обычно принято относить к одной из программных архитектур, имеющих свои плюсы и минусы.
45. Обобщенная технология работы с СУБД. Основные этапы работы с БД.
Технология работы с базами данных имеет несколько этапов, именно:
· построение инфологической модели БД
· создание структуры таблиц базы данных
· вывод информации из БД.
На первом этапе создания базы данных строится инфологическая модель. Для построения инфологической модели необходимо сделать анализ существующей базы данных, определить источник данных, посмотреть решаемые с помощью базы задачи и продумать проблемы, которые следует решать в будущем. Идентифицировав данные и задачи, которые следует решать, необходимо разделить их на группы, которые впоследствии станут таблицами БД.
Создание структуры таблиц базы данных предполагает определение групп и типов данных, которые будут храниться в таблицах, задание размера полей в каждой таблице и определение ключей — общих элементов таблиц.
Ввод и редактирование данных могут производиться двумя способами: с помощью специальных форм и непосредственно в таблицу без использования форм.
Обработка информации в базе данных производится путем выполнения запросов или в процессе выполнения специально разработанной программы.
Запрос - это команда, формулируемая для СУБД, которая требует представить определенную указанную в запросе информацию. Язык SQL — это структурированный язык запросов (Structured Query Language). Запросы являются наиболее часто используемым аспектом SQL. Все запросы в SQL конструируются на базе команды SELECT (выбор).
Результатом выполнения запроса является таблица с временным набором данных (динамический набор). Записи динамического набора могут включать поля из одной или нескольких таблиц. На основе запроса можно построить отчет или форму.
Для вывода информации из базы данных существует специальное средство — отчеты. Они позволяют:
· включать в отчет выборочную информацию из таблиц базы данных;
· добавлять информацию, не содержащуюся в базе;
· выводить итоговую информацию из базы данных;
· располагать выводимую информацию в любом удобном виде;
включать в отчет информацию из разных таблиц.
46. Назначение и классификация компьютерных сетей.
Отдельные компьютеры при соединении между собой образуют новое качество по управлению объектами и по образованию информации.
Первые компьютерные сети создавались для реализации процессов производства, вскоре стали использоваться для управленческой деятельности. Назначение компьютерных сетей определяется двумя функциями:
- Обеспечение совместного использования аппаратных и программных ресурсов.
- Обеспечение совместного доступа к ресурсам данных.
Компьютерные сети нужно отличать от Многомашинного Вычислительного Комплекса (МВК). МВК - это группа установленных рядом и соединенных ЭВМ, которые выполняют единый информационно-вычислительный процесс. Для компьютерной сети единого процесса или единой задачи не формулируется. Для создания компьютерной сети необходимо специальное сетевое, аппаратное и программное обеспечение. Для обмена информацией в компьютерной сети используются протоколы. Протокол - это стандарт совместимости передаваемой по сети информации. различают стандарты совместимости аппаратуры (аппаратные протоколы) и стандарты совместимости программ и данных (программные протоколы).
Существуют два типа технологии передачи:
· сети с передачей от узла к узлу.
Сети с передачей от узла к узлусостоят из большого количества соединенных пар машин. В такой сети пакету необходимо пройти через ряд промежуточных машин, чтобы добраться до пункта назначения. Часто при этом существует несколько возможных путей от источника к получателю.
Обычно небольшие сети используют широковещательную передачу, тогда как в крупных сетях применяется передача от узла к узлу.
По территориальному признаку компьютерные сети разделяются на 3 класса:
- Глобальные сети (GAN)
- Региональные сети (RAN)
- Локальные сети (LAN - Local Network Area)
Ø Локальными сетями (ЛВС — локальные вычислительные сети или LAN — Local Area Network) называют сети, размещающиеся, как правило, в одном здании или на территории какой-либо организации размерами до нескольких километров. Их часто используют для предоставления совместного доступа компьютеров к ресурсам (например, принтерам) и обмена информацией. Локальные сети отличаются от других сетей тремя характеристиками: размерами, технологией передачи данных и топологией. Обычные ЛВС имеют пропускную способность канала связи от 10 до 100 Мбит/с, небольшую задержку − десятые доли мкс и очень мало ошибок.
Ø Муниципальные или региональные сети (MAN — Metropolitan AN) являются увеличенными версиями локальных сетей и обычно используют схожие технологии. Такая сеть может объединять несколько предприятий корпорации или город. Муниципальная сеть может поддерживать передачу цифровых данных, звука и включать в себя кабельное телевидение. Обычно муниципальная сеть не содержит переключающих элементов для переадресации пакетов во внешние линии, что упрощает структуру сети.
47. Локальные вычислительные сети, назначение, состав.
Локальная вычислительная сеть представляет собой систему распределенной обработки данных, охватывающую небольшую территорию (диаметром до 10 км) внутри учреждений, НИИ, вузов, банков, офисов и т.п., это система взаимосвязанных и распределенных на фиксированной территории средств передачи и обработки информации, ориентированных на коллективное использование общесетевых ресурсов — аппаратных, информационных, программных. ЛВС можно рассматривать как коммуникационную систему, которая поддерживает в пределах одного здания или некоторой ограниченной территории один или несколько высокоскоростных каналов передачи информации, предоставляемых подключенным абонентским системам (АС) для кратковременного использования.
В обобщенной структуре ЛВС выделяются совокупность абонентских узлов, или систем (их число может быть от десятков до сотен), серверов и коммуникационная подсеть (КП).
Основными компонентами сети являются кабели (передающие среды), рабочие станции (АРМ пользователей сети), платы интерфейса сети (сетевые адаптеры), серверы сети.
Рабочими станциями (PC) в ЛВС служат, как правило, персональные компьютеры (ПК). На PC пользователями сети реализуются прикладные задачи, выполнение которых связано с понятием вычислительного процесса.
Серверы сети — это аппаратно-программные системы, выполняющие функции управления распределением сетевых ресурсов общего доступа, которые могут работать и как обычная абонентская система. В качестве аппаратной части сервера используются достаточно мощный ПК, мини-ЭВМ, большая ЭВМ или компьютер, спроектированный специально как сервер. В ЛВС может быть несколько различных серверов для управления сетевыми ресурсами, однако всегда имеется один (или более) файл-сервер (сервер баз данных) для управления внешними ЗУ общего доступа и организации распределенных баз данных (РБД).
Рабочие станции и серверы соединяются с кабелем коммуникационной подсети с помощью интерфейсных плат — сетевых адаптеров (СА). Основные функции СА: организация приема (передачи) данных из (в) PC, согласование скорости приема (передачи) информации (буферизация), формирование пакета данных, параллельно-последовательное преобразование (конвертирование), кодирование (декодирование) данных, проверка правильности передачи, установление соединения с требуемым абонентом сети, организация собственно обмена данными. В ряде случаев перечень функций СА существенно увеличивается, и тогда они строятся на основе микропроцессоров и встроенных модемов.
В ЛВС в качестве кабельных передающих сред используются витая пара, коаксиальный кабель и оптоволоконный кабель.
Кроме указанного, в ЛВС используется следующее сетевое оборудование:
приемопередатчики (трансиверы) и повторители (репитеры) — для объединения сегментов локальной сети с шинной топологией;
концентраторы (хабы) — для формирования сети произвольной топологии (используются активные и пассивные концентраторы);
мосты — для объединения локальных сетей в единое целое и повышения производительности этого целого путем регулирования трафика (данных пользователя) между отдельными подсетями;
модемы (модуляторы — демодуляторы) — для согласования цифровых сигналов, генерируемых компьютером, с аналоговыми сигналами типичной современной телефонной линии;
анализаторы — для контроля качества функционирования сети;
сетевые тестеры — для проверки кабелей и отыскания неисправностей в системе установленных кабелей.
Типы ЛВС. Для деления ЛВС на группы используются определенные классификационные признаки
По назначению ЛВС делятся на информационные (информационно-поисковые), управляющие (технологическими, административными, организационными и другими процессами), расчетные, информационно-расчетные, обработки документальной информации и др.
По типам используемых в сети ЭВМ их можно разделить на неоднородные, где применяются различные классы (микро-, мини-, большие) и модели (внутри классов) ЭВМ, а также различное абонентское оборудование, и однородные, содержащие Одинаковые модели ЭВМ и однотипный состав абонентских средств.
По организации управления однородные ЛВС различаются на сети с централизованным и децентрализованным управлением.
По скорости передачи данных
· ЛВС с малой пропускной способностью
· ЛВС со средней пропускной способностью
· ЛВС с большой пропускной способностью
К наиболее типичным областям применения ЛВС относятся следующие:
Обработка текстов
Понятие базы данных невозможно рассматривать без основных ее структурных элементов – поля, записи, файла (таблицы).


Поле является элементарной единицей логической организации данных, соответствующей неделимой единице информации – реквизиту.
Полем базы данных является столбец таблицы, который содержит значения определенного свойства.
Поле описывается с помощью следующих характеристик:
-
имя – имя соответствующего свойства (например, №, Фамилия, Адрес, Телефон, Название компании, Место работы, Дата рождения);
тип – определяет тип данных, которые содержит поле. В базах данных допускается создание полей, которые могут содержать данные таких основных типов:
- счетчик – данные целого типа, задающиеся автоматически при вводе пользователем записей, которые он не может изменить;
- текстовый – данные текстового типа, которые могут содержать до 255 символов;
- числовой – данные любого числового типа;
- дата/время – данные, которые содержат информацию о дате и/или времени;
- денежный – данные, которые представляют числа в денежном формате;
- логический – данные, которые могут принимать одно из двух значений – Истина (Да) или Ложь (Нет);
- поле объекта OLE – данные, которые содержат изображение;
- гиперссылка – данные, которые содержат ссылку на ресурсыИнтернета (например, ссылку на веб-сайт).
длина – определяется максимально возможным числом символов (например, 50 байт);
Готовые работы на аналогичную тему
Каждое поле любого типа характеризуется набором свойств. Наиболее важные свойства полей:
- размер, определяющий максимальную длину числового или текстового поля;
- формат, устанавливающий формат данных поля;
- обязательное поле, указывающее на то, что данное поле является обязательным к заполнению.
Каждая таблица базы данных, как правило, содержит не меньше одного ключевого поля, содержимое которого является уникальным для каждой записи данной таблицы. Ключевое поле однозначно идентифицирует каждую запись таблицы.
Ключевое поле является полем, значение которого однозначно определяет запись в таблице.
Зачастую ключевые поля имеют тип данных счетчик, но иногда бывает удобным использовать поля другого типа (например, код заказа, идентификационный номер и т.п.).
Запись
Строки таблицы представляют собой записи об объекте. Записи в свою очередь разбиваются столбцами таблицы на поля. Таким образом, каждая является набором значений, которые содержатся в полях.
Запись – строка таблицы, которая содержит набор значений свойств, находящийся в полях базы данных.
Запись является совокупностью логически связанных полей.
Экземпляр записи представляет собой отдельную реализацию записи, содержащую конкретные значения ее полей.
Файл (таблица) базы данных представляет собой совокупность экземпляров записей одной структуры.
Описывается логическая структура записи файла последовательностью расположения полей записи и их основных характеристик.
Логическая структура записи файла

Структура записи файла содержит информацию о полях, которые содержат значения первичных ключей (ПК), однозначно идентифицирующих экземпляр записи, и вторичных ключей (ВК), выполняющих роль поисковых признаков или признаков группы (с помощью вторичного ключа возможен поиск нескольких записей).
Получи деньги за свои студенческие работы
Курсовые, рефераты или другие работы
Автор этой статьи Дата написания статьи: 28.06.2016
Анастасия Николаевна Королева
Автор24 - это сообщество учителей и преподавателей, к которым можно обратиться за помощью с выполнением учебных работ.

Если всеми нами известный табличный процессор Excel специально создан для решения задач обработки табличных данных, то существуют системы (приложения) для решения иных классов задач. В частности, очень большую роль играют сейчас программы (приложения, системы), цепь которых – хранение данных и выдача данных по запросу пользователя. Использование компьютеров именно для решения этого класса задач становится всё более массовым явлением.
Смело можно сказать, что такие задачи и необходимость их решения существуют в любой фирме, на любом предприятии. Основное понятие для подобного круга задач – база данных. Базой данных называется файл или группа файлов стандартной структуры, служащая для хранения данных.
Для разработки программ, систем программ, работающих с базами данных, используются специальные средства – системы управления базами данных (СУБД).
СУБД включает, как правило, специальный язык программирования и все прочие средства, необходимые для разработки указанных программ.
В настоящее время наиболее известными СУБД являются: Oracle Database, MS SQL Server, MySQL (MariaDB) и ACCESS. Последняя входит в состав профессионального офисного пакета Microsoft Office.
Это современные системы с большими возможностями, предназначенные для разработки сложных программных комплексов, и знакомство с ними для пользователя ЭВМ исключительно полезно, но в рамках настоящего пособия осуществить его затруднительно.
Понятие базы данных
База данных (БД) – это совокупность массивов и файлов данных, организованная по определённым правилам, предусматривающим стандартные принципы описания, хранения и обработки данных независимо от их вида.
База данных (БД) – совокупность организованной информации, относящейся к определённой предметной области, предназначенная для длительного хранения во внешней памяти компьютера и постоянного применения.

Виды баз данных
- Фактографическая – содержит краткую информацию об объектах некоторой системы в строго фиксированном формате;
- Документальная – содержит документы самого разного типа: текстовые, графические, звуковые, мультимедийные;
- Распределённая – база данных, разные части которой хранятся на различных компьютерах, объединённых в сеть;
- Централизованная – база данных, хранящихся на одном компьютере;
- Реляционная – база данных с табличной организацией данных;
- Неструктурированная (NoSQL) - база данных, в которой делается попытка решить проблемы масштабируемости и доступности за счёт атомарности (англ. atomicity) и согласованности данных, но не имеющих четкой (реляционной) структуры.
Одно из основных свойств БД – независимость данных от программы, использующих эти данные. Работа с базой данных требует решения различных задач, основные из них следующие:
- создание базы;
- запись данных в базу;
- корректировка данных;
- выборка данных из базы по запросам пользователя.
Задачи этого списка называются стандартными .
Следующее понятие, связанное с базой данных: программа для работы с базой данных – это программа, которая обеспечивает решение требуемого комплекса задач. Любая подобная программа должна уметь решать все задачи стандартного набора.
База данных в разных системах имеет различную структуру.
В ПВЭМ обычно используются реляционные БД – в таких базах файл является по структуре таблицей. В ней столбцы называются полями, строки – записями.
В БД содержатся банные некоторого множества объктов. Каждая запись содержит данные одного объекта. Каждая такая БД определяется именем файла, списком полей, шириной полей. Например, БД Школа (Ученик, Класс, Адрес).
Примером БД может служить расписание движения поездов или автобусов. Здесь каждая строчка – запись отражает данные строго одного объекта. База включает поля: номер рейса, маршрута следования, время отправления и т.д.
Классическим примером БД является и телефонный справочник. Запрос к базе данных – это предписание, указывающее, какие данные пользователь желает получить из базы.
Некоторые запросы могут представлять собой серьёзную задачу, для решения которой потребляется составлять сложную программу. Например, запрос к базе – автобусному расписанию: определить разницу в среднем интервале отправления автобусов из Ростова в Таганрог и из Ростова в Шахты.
Объекты для работы с базами данных
Для создания приложения, позволяющего просматривать и редактировать базы данных, нам потребуется три звена:
- набор данных
- источник данных
- визуальные элементы управления
В нашем случае эта триада реализуется в виде:
Table подключается непосредственно к таблице в базе данных. Для этого нужно установить псевдоним базы в свойстве DataBaseName и имя таблицы в свойстве TableName, а затем активизировать связь: свойство Active = true .
А зачем нужен компонент – посредник? Почему бы сразу не подключаться к Table?
Допустим, несколько визуальных компонентов – таблица, поля ввода и т.п. подключены к таблице. А нам нужно быстро переключить их все на другую подобную таблицу. С DataSource это сделать несложно - достаточно просто поменять свойство DataSe t, а вот без DataSource пришлось бы менять указатели у каждого компонента.
Приложения баз данных – нить, связывающая БД и пользователя:
БД => набор данных –=> источник данных => визуальные компоненты => пользователь
- Table(таблица, навигационный доступ)
- Query(запрос, реляционный доступ)
- Сетки DBGrid, DBCtrlGrid
- Навигатор DBNavigator
- Всяческие аналоги Lable, Editи т.д.
- Компоненты подстановки
Типы данных в базах
В Access можно определить следующие типы полей:
Типы данных в таблицах Access
Не надо забывать про индексы. Связывать таблицы. Связь с обеспечением целостности контролирует каскадное удаление и модификацию данных.
Монопольный доступ к БД нужен для того, чтобы производить в ней фундаментальные изменения.
Основные понятия и элементы баз данных
Базы данных понадобились тогда, когда возникла потребность хранить большие объёмы однотипной информации, уметь её оперативно использовать. Базами данных (в широком понимании этого слова) пользовались на протяжении всей истории жрецы, чиновники, купцы, ростовщики, алхимики.
Основное требование к базам данных – удобство доступа к данным, возможность оперативно получить исчерпывающую информацию по любому интересующему вопросу (важно не только то, что информация содержится в базе, важно то, насколько она хорошо структирована и целостна).
Лишь только появились и распространились компьютеры, почти сразу на них возложили тяжёлый и кропотливый труд по обработке и структурированию данных, появились базы данных (БД) в их нынешнем понимании.
Согласно современным требованиям к базам данных, информация, содержащаяся в них, должна быть:
- непротиворечивой (не должно быть данных, противоречащих друг другу);
- неизбыточной (следует избегать ненужного дублирования информации в базе, избыточность может привести к противоречивости – например, если какие – то данные изменяют, а их копию в другой части базы забыли изменить);
- целостной (все данные должны быть связаны, не должно быть ссылок на несуществующие в базе данные)
Таблица представляет собой двумерный массив, в котором хранятся данные. Столбцы таблицы (в рамках принятых обозначений БД) называются полями, строки – записями. Количество полей таблицы фиксировано, количество записей – нет. Фактически таблица – нефиксированный массив записей с одинаковой структурой полей в каждой записи. Добавить в таблицу новую запись не составляет труда, а то время как добавление нового поля влечёт за собой рестрктуризацию всей таблицы и может вызвать определённые трудности. В качестве значений полей в записях могут храниться числа, строки, картинки и т.д. Таблицы баз данных хранятся на жёстком диске (на локальном компьютере или на сервере баз данных – в зависимости от типа БД). Одной таблице соответствуют обычно несколько файлов – один основной и несколько вспомогательных. Тонкости организации таблиц зависят от используемого формата (dBase, Paradox, InterBase, Microsoft Access и т.д.)
Ключ – поле или комбинация полей таблицы, значения в которых однозначно определяют запись. Ключ потому так и называется, что, имея значения ключевых полей, можно однозначно получить доступ к нужной записи. Таким образом, ключи чрезвычайно полезны для связи таблиц. Записывая значения ключа в отведённые поля подчинённой таблицы и тем самым, задавая ссылку, обеспечиваем связь двух записей – записи в главной таблице и записи в подчинённой таблице. В одной записи подчинённой таблицы может находиться и несколько ссылок на записи главной таблицы. Например, в школьном журнале может быть таблица – список дежурств, где в каждой записи содержатся фамилии и имена (ключ их двух полей) нескольких дежурных. Так осуществляется связь различных записей главной таблицы и реализуется достаточно сложная структура данных. В школьной практике в качестве ключевых полей используются имена и фамилии, но в БД лучше отводить специальные ключевые поля – индивидуальные номера (коды) записей. Это гарантированно уберегает от возможных проблем с однофамильцами. В школе же, где не требуется такая компьютерная чёткость, появление в одном классе двух учеников с одинаковыми именами и фамилиями – очень редкое событие, поэтому можно простить подобное техническое упущение. Кроме связывания, ключи могут использоваться для прямого доступа к записям, ускорения работы с таблицей.
Индекс – поле, так же, как и ключ, специально выделенное в таблице, данные в котором, однако, могут повторяться. Они также служат для ускорения доступа и, кроме того, для сортировки и выборок.
Нормальные формы были придуманы, скорее, для автоматизации процесса создания баз данных, нежели как руководство тем, кто создаёт их вручную (автоматическое проектирование больших баз данных может производиться с помощью специальных систем программ – средств (CASE). Реально при ручной разработке проектировщик сразу же задумывает необходимую структуру, планирует нужные таблицы, а не идёт от одной большой таблицы. Нормальные формы фактически формализуют интуитивно понятые требования к организации данных, помогая, прежде всего, избежать избыточного дублирования данных.
Первая нормальная форма:
- информация в полях неделимая (к примеру, имя и фамилия должны быть разными полями, а не одним);
- в таблице нет повторяющихся групп полей
Вторая нормальная форма:
- выполнена первая форма;
- любое неключевое поле однозначно идентифицируется ключевыми полями (фактически, требование наличия ключа)
Третья нормальная форма:
- выполнена вторая форма
- неключевые поля должны однозначно идентифицироваться только ключевыми полями (это значит, что данные, не зависящие от ключа, должны быть вынесены в отдельную таблицу)
Требование третьей нормальной формы имеет тот смысл, что таблицу с полями (Имя, Фамилия, Класс, Классный руководитель) необходимо разбить на две таблицы (Имя, Фамилия, Класс) и (Класс, Классный руководитель), поскольку поле Класс однозначно определяет поле Классный руководитель (а согласно третьей форме, однозначно определять должны только ключи).
Для более глубокого понимания тонкостей проведения операций с записями в таблицах необходимо иметь понятия о способах доступа, транзакциях и бизнес-правилах.
Способы доступа определяют, как технически производятся операции с записями. Способы доступа выбираются программистом во время разработки приложения. Навигационный способ основан на последовательной обработке нужных записей поодиночке. Он обычно используется для небольших локальных таблиц. Реляционный способ основан на обработке сразу набора записей с помощью SQL-запросов. Он используется для больших удалённых БД.
Транзакции определяют надёжность выполнения операций по отношению к сбоям. В транзакцию объединяется последовательность операций, которая либо должна быть выполнена полностью, либо не выполнена совсем. Если во время выполнения транзакции произошёл сбой, то все результаты всех операций, входящих в неё отменяются. Это гарантирует то, что не нарушается корректность базы данных даже в случае технических (а не программных) сбоев.
Бизнес-правила определяют правила проведения операций и представляют механизмы управления БД. Задавая возможные ограничения на значения полей, они также вносят свой вклад в поддержание корректности базы. Несмотря на возможные ассоциации с бизнесом как коммерцией, бизнес-правила не имеют к нему прямого отношения и просто являются правилами управления базами данных.
Читайте также: