
Доклад кодировки русских букв
Обновлено: 30.06.2024
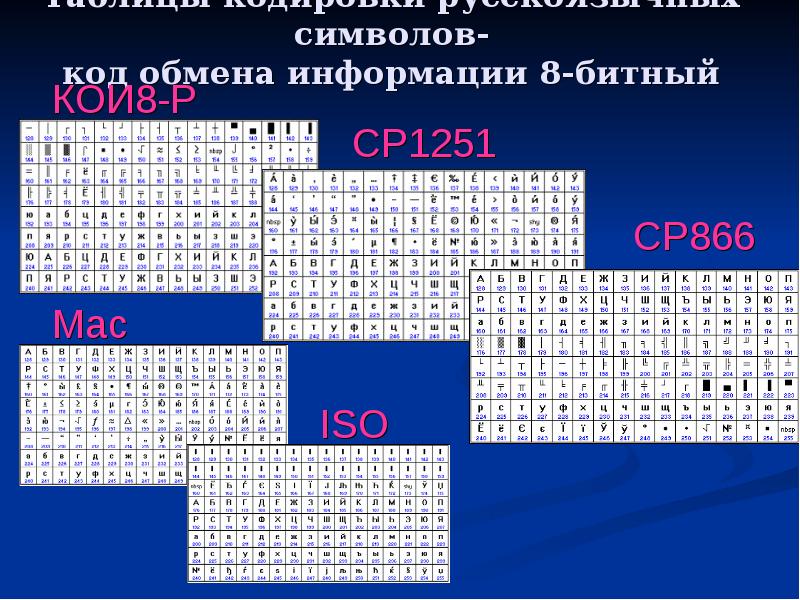
В настоящее время наиболее широко используются пять (!) различных таблиц кодировки для формального представления русских букв:
- I. ISO 8859-5 - международный стандарт;
- II. Кодовая страница 866 (Microsoft CP866) - используется в MS-DOS;
- III. Кодовая страница 1251 (Microsoft CP1251) для Microsoft Windows;
- IV. На базе ГОСТ КОИ-8, koi8 -r - применяется в мире Unix;
- V. Unicode - используется в Microsoft Windows, Unix и клонах Unix.
Основная кодировка ГОСТ (государственный стандарт СССР) от 1987 года создана на основе рекомендаций ISO и в дальнейшем стала основой для представления знаков русских букв в Unicode. В ней и в кодировках II, III и V все буквы кроме ё и Ё расположены в алфавитном порядке. На практике эту кодировку можно встретить только на старых IBM PC совместимых компьютерах ЕС-1840 и в некоторых принтерах. Internet браузеры обычно поддерживают ее наряду с кодировками II-IV.
Кодировка CP866, разработанная на основе альтернативной кодировки ГОСТ, создана специально для ОС MS-DOS, в которой часто используются символы псевдографики. В этой кодировке эти символы имеют те же коды, что и в стандартном IBM PC совместимом компьютере.
Альтернативная кодировка ГОСТ, которая имеет два варианта, совпадает с CP866 по позициям для букв русского алфавита и знакам псевдографики. Основная кодировка ГОСТ совпадает с ISO 8859-5 только по всем знакам русских букв, кроме заглавной буквы Ё.
Использование CP1251 обусловлено почти исключительно влиянием на компьютерные технологии разработок фирмы Microsoft. В ней наиболее полно по сравнению с I, II, IV представлены такие символы как , " />
, №, различные виды кавычек и тире и т. п.
Кодировка koi8 -r основана на стандартах по обмену информацией, используемых на компьютерах под управлением ОС Unix, CP/M и некоторых других с середины 1970-х. В 1993 она стандартизирована в Internet документом RFC1489.
Кодировка Unicode опирается на каталог символов UCS (Universal Character Set ) стандарта ISO 10646. UCS может содержать до 2 31 различных знаков. Коды UCS -2 - 2-байтные, UCS -4 - 4-байтные. Используются также коды переменной длины UTF-8 (Unicode Transfer Format) - 1 -6-байтные, наиболее совместимые с ASCII, и UTF-16 - 2 или 4-байтные. Unicode в прикладных программах реализуется лишь частично, и в полном объеме пока нигде не поддерживается. В Linux используется UTF-8.
Достаточно широко используется кодирование на основе ASCII:
В кодировке VI нет видимого символа для Ъ.
Далее следует таблица , в которой представлены все перечисленные способы кодирования букв русского алфавита. В этой таблице в колонке 1 находятся символы букв, в колонке 2 часть названия букв в Unicode 3.2 (названия строчных кириллических букв начинается словами CYRILLIC SMALL LETTER , а заглавных - CYRILLIC CAPITAL LETTER , т. о., полное название буквы Д - CYRILLIC CAPITAL LETTER DE), в колонках с I по V коды десятичные и шестнадцатеричные соответствующих таблиц кодировки , а в колонке VI - символ ASCII для КОИ-7.
Кроме перечисленных можно встретить еще используемую до введения кодировок ГОСТ болгарскую кодировку, называемую также MIC , Interprog или "старый вариант ВЦ АН СССР". На компьютерах под управлением Macintosh OS используется также своя собственная таблица кодировки для русских букв, по своему набору знаков почти совпадающая с CP1251.
Кодирование текстовой информации
Одна и та же информация может быть представлена (закодирована) в нескольких формах. C появлением компьютеров возникла необходимость кодирования всех видов информации, с которыми имеет дело и отдельный человек, и человечество в целом. Но решать задачу кодирования информации человечество начало задолго до появления компьютеров. Грандиозные достижения человечества - письменность и арифметика - есть не что иное, как система кодирования речи и числовой информации. Информация никогда не появляется в чистом виде, она всегда как-то представлена, как-то закодирована.
Двоичное кодирование – один из распространенных способов представления информации. В вычислительных машинах, в роботах и станках с числовым программным управлением, как правило, вся информация, с которой имеет дело устройство, кодируется в виде слов двоичного алфавита.
Начиная с конца 60-х годов, компьютеры все больше стали использоваться для обработки текстовой информации, и в настоящее время основная доля персональных компьютеров в мире (и большая часть времени) занята обработкой именно текстовой информации. Все эти виды информации в компьютере представлены в двоичном коде, т. е. используется алфавит мощностью два (всего два символа 0 и 1). Связано это с тем, что удобно представлять информацию в виде последовательности электрических импульсов: импульс отсутствует (0), импульс есть (1).
Такое кодирование принято называть двоичным, а сами логические последовательности нулей и единиц - машинным языком.
С точки зрения ЭВМ текст состоит из отдельных символов. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа "=", "(", "&" и т.п. и даже (обратите особое внимание!) пробелы между словами.

Т радиционно для кодирования одного символа используется количество информации, равное 1 байту, т. е. I = 1 байт = 8 бит. При помощи формулы, которая связывает между собой количество возможных событий К и количество информации I, можно вычислить сколько различных символов можно закодировать (считая, что символы - это возможные события): К = 2 I = 2 8 = 256, т. е. для представления текстовой информации можно использовать алфавит мощностью 256 символов.
Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и строчные буквы русского и латинского алфавита, цифры, знаки, графические символы и пр.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертанию, а компьютер - по их коду.
Удобство побайтового кодирования символов очевидно, поскольку байт - наименьшая адресуемая часть памяти и, следовательно, процессор может обратиться к каждому символу отдельно, выполняя обработку текста. С другой стороны, 256 символов – это вполне достаточное количество для представления самой разнообразной символьной информации.
В процессе вывода символа на экран компьютера производится обратный процесс — декодирование, то есть преобразование кода символа в его изображение. Важно, что присвоение символу конкретного кода — это вопрос соглашения, которое фиксируется в кодовой таблице.
Теперь возникает вопрос, какой именно восьмиразрядный двоичный код поставить в соответствие каждому символу. Понятно, что это дело условное, можно придумать множество способов кодировки.
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления.
Виды таблиц кодировок
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
Для разных типов ЭВМ используются различные таблицы кодировки.
В качестве международного стандарта принята кодовая таблица ASCII (American Standard Code for Information Interchange - Американский стандартный код для информационного обмена), кодирующая первую половину символов с числовыми кодами от 0 до 127 ( коды от 0 до 32 отведены не символам, а функциональным клавишам).
Таблица кодов ASCII делится на две части.
Международным стандартом является лишь первая половина таблицы, т.е. символы с номерами от 0 (00000000), до 127 (01111111).
Структура таблицы кодировки ASCII
Порядковый номер
Символы с номерами от 0 до 31 принято называть управляющими.
Их функция – управление процессом вывода текста на экран или печать, подача звукового сигнала, разметка текста и т.п.
Стандартная часть таблицы (английский). Сюда входят строчные и прописные буквы латинского алфавита, десятичные цифры, знаки препинания, всевозможные скобки, коммерческие и другие символы.
Символ 32 - пробел, т.е. пустая позиция в тексте.
Все остальные отражаются определенными знаками.
Альтернативная часть таблицы (русская).
Вторая половина кодовой таблицы ASCII, называемая кодовой страницей (128 кодов, начиная с 10000000 и кончая 11111111), может иметь различные варианты, каждый вариант имеет свой номер.
Кодовая страница в первую очередь используется для размещения национальных алфавитов, отличных от латинского. В русских национальных кодировках в этой части таблицы размещаются символы русского алфавита.

Обращается внимание на то, что в таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита.
Для букв русского алфавита также соблюдается принцип последовательного кодирования.


От начала 90-х годов, времени господства операционной системы MS DOS, остается кодировка CP866 ("CP" означает "Code Page", "кодовая страница").

Компьютеры фирмы Apple, работающие под управлением операционной системы Mac OS, используют свою собственную кодировку Mac.

Кроме того, Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве стандарта для русского языка еще одну кодировку под названием ISO 8859-5.

Наиболее распространенной в настоящее время является кодировка Microsoft Windows, обозначаемая сокращением CP1251. Введена компанией Microsoft; с учетом широкого распространения операционных систем (ОС) и других программных продуктов этой компании в Российской Федерации она нашла широкое распространение.

С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется Unicode.

Это 16-разрядная кодировка, т.е. в ней на каждый символ отводится 2 байта памяти. Конечно, при этом объем занимаемой памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.
Внутреннее представление слов в памяти компьютера
с помощью таблицы ASCII
Иногда бывает так, что текст, состоящий из букв русского алфавита, полученный с другого компьютера, невозможно прочитать - на экране монитора видна какая-то "абракадабра". Это происходит оттого, что на компьютерах применяется разная кодировка символов русского языка.

Таким образом, каждая кодировка задается своей собственной кодовой таблицей. Как видно из таблицы, одному и тому же двоичному коду в различных кодировках поставлены в соответствие различные символы.
К счастью, в большинстве случаев пользователь не должен заботиться о перекодировках текстовых документов, так как это делают специальные программы-конверторы, встроенные в приложения.
Вы можете изучить и скачать доклад-презентацию на тему Кодирование текстовой информации. Кодировки русского алфавита. Презентация на заданную тему содержит 17 слайдов. Для просмотра воспользуйтесь проигрывателем, если материал оказался полезным для Вас - поделитесь им с друзьями с помощью социальных кнопок и добавьте наш сайт презентаций в закладки!
















Цели урока: Обучающие: познакомить учащихся со способами кодирования и декодирования текстовой информации с помощью кодовых таблиц и компьютера, формирование общеучебные умений и навыков, стимулировать интерес учащихся к данной теме и учебном процессе в целом. Развивающие: развитие коммуникативно-технических умений, развитие умения применять полученные знания при решении задач различной направленности, развитие умения пользоваться предложенными инструментами. Воспитательные: воспитывать добросовестное отношение к труду, инициативность, уверенность в своих силах.
преобразование входной информации в форму, воспринимаемую компьютером, т.е. двоичный код. преобразование входной информации в форму, воспринимаемую компьютером, т.е. двоичный код.
Для кодирования одного символа требуется один байт информации. Учитывая, что каждый бит принимает значение 1 или 0, получаем, что с помощью 1 байта можно закодировать 256 различных символов. N=2i N – мощность алфавита 28=256 I – информационный вес
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера (коды) Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера (коды)
Таблица кодировки ASCII является стандартной, и ее понимают абсолютно все программы, работающие с текстами.
Таблица кодировки Unicode Стандарт кодирования Unicode отводит на каждый символ 2 байта, что позволяет закодировать многие алфавиты в одной таблице. N=2I=216=65 536
В настоящее время существует 5 кодовых таблиц для русских букв (Windows, MS-DOS, КОИ-8, Mac, ISO), поэтому тексты, созданные в одной кодировке, не будут правильно отображаться в другой. В настоящее время существует 5 кодовых таблиц для русских букв (Windows, MS-DOS, КОИ-8, Mac, ISO), поэтому тексты, созданные в одной кодировке, не будут правильно отображаться в другой.
Декодировать текст с помощью кодовой таблицы ASCII: Декодировать текст с помощью кодовой таблицы ASCII: 99 111 109 112 117 116 101 114
Цель: научиться определять числовые коды символов и вводить символы с помощью числовых кодов. Цель: научиться определять числовые коды символов и вводить символы с помощью числовых кодов.
п. 3.1; Произвести кодирование стихотворения из 4-х строк (до 100 символов) п. 3.1; Произвести кодирование стихотворения из 4-х строк (до 100 символов)
Процесс обработки текста. Элементы теории кодирования. Понятие о кодировании информации. Кодирование текстовой информации байтами. Кодировочные таблицы, стандартная кодировка ASCII. Кодовая таблица Windows (CP-1251). Альтернативная кодовая таблица.
| Рубрика | Программирование, компьютеры и кибернетика |
| Вид | реферат |
| Язык | русский |
| Дата добавления | 09.10.2009 |
| Размер файла | 422,3 K |
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
1. Процесс обработки текста
2. Элементы теории кодирования
2.1 Понятие о кодировании информации
2.2 Кодирование и декодирование
3. Кодирование текстовой информации байтами
4. Кодировочные таблицы
4.1 Стандартная кодировка ASCII
4.2 Кодовая таблица Windows (CP-1251)
4.3 Альтернативная кодовая таблица
Актуальность. В данной работе речь пойдет о том, без чего нельзя записать, передать или сохранить информацию. Все это основано на понятии кодирование.
Понятие кодирования достаточно универсально, так как этот процесс используется на всех этапах обработки информации: при сборе, передаче, обработке, хранении и представлении.
Само по себе понятие кодирования информации может быть отнесено к области абстрактных категорий подобно математическим формулам, что позволяет строить формальные правила кодообразования.
Задачи кодирования информации решались задолго до появления компьютеров. Коды, как средство тайнописи появились в глубокой древности. Да и сами древние алфавиты по сути - средства кодирования. Кодирование можно рассматривать как в широком, так и в узком смысле слова.
Чтобы передать текстовую информацию, её необходимо предварительно преобразовать.
Объект: процесс обработки и кодировки текста.
Предмет: русские кодировки текста.
Цель: рассмотреть и проанализировать процесс кодирования текстовой информации.
- провести анализ литературы по теме исследования;
- рассмотреть процесс обработки текста;
- рассмотреть сущность понятия кодирования информации;
- охарактеризовать процесс кодирования и декодирования;
- проанализировать кодирование текстовой информации байтами;
- выделить основные кодировочные таблицы: стандартную кодировку ASCII, кодовую таблицу Windows (CP-1251), альтернативную кодовую таблицу.
1. Процесс обработки текста
Обработка (преобразование) текста -- это процесс изменения формы представления текста или его содержания.
Обработка текста всегда осуществляется с какой-либо целью.
Процессы изменения формы представления текста часто сводятся к процессам его кодирования и декодирования и проходят одновременно с процессами сбора и передачи информации.
Процесс изменения содержания текста включает в себя такие процедуры, как численные расчеты, редактирование, упорядочивание, обобщение, систематизация и т.д.
Систему, в которой наблюдателю доступны лишь входные и выходные величины, а структура и внутренние процессы неизвестны, называют черным ящиком [3, c. 87].
Обработка текста по принципу “черного ящика” - процесс, в котором пользователю важна и необходима лишь входная и выходная информация, но правила, по которым происходит преобразование, его не интересуют и не принимаются во внимание.
Если правила преобразования текста строго формализованы и имеется алгоритм их реализации, то можно построить устройство для автоматизированной обработки текста.
Возможность автоматизированной обработки текста основывается на том, что преобразование текста по формальным правилам не подразумевает его осмысления.
В вычислительной технике устройством обработки текста является процессор.
Обработка текста - это процесс, происходящий во времени.
Если он подчиняется заданному темпу поступления входной информации и допустимому пределу задержки в выработке информации на выходе, то говорят об обработке в реальном масштабе времени.
Наиболее простой формой обработки текста является последовательная обработка, производимая одним процессором, в котором в любой момент времени происходит не более одного события.
При наличии в системе нескольких процессоров, работающих одновременно, говорят о параллельной обработке текстовой информации.
2. Элементы теории кодирования
Одни и те же сведения могут быть представлены, закодированы в нескольких разных формах и, наоборот, совершенно разные сведения могут быть представлены в похожей форме [5, c. 91].
Чтобы передать информацию, её необходимо предварительно преобразовать.
В систему связи необходимо ввести устройства для кодирования и декодирования информации.
При передаче по каналу связи возникают ошибки, связанные с разными причинами, но все они приводят к тому, что получатель принимает искаженную информацию. Для того чтобы организовать нормальную работу информационного канала связи необходимо решить следующие проблемы:
обнаружить ошибки, если они возникают;
исправлять найденные ошибки;
защищать информацию, передающуюся по каналам связи;
ускорять передачу информации по каналу связи [1, c. 37].
Из перечисленных проблем теория кодирования исследует первую и вторую. Третьей проблемой занимается криптография. Четвертая же является прикладной для криптографии и теории кодирования как параметр, с помощью которого определяется качество криптографии и кодирования.
2.1 Понятие о кодировании информации
Информация передается в виде сигналов. Когда мы разговариваем с другими людьми, то улавливаем звуковые сигналы. Если мы смотрим в окно, наш глаз принимает световые потоки, отраженные от объектов окружающей природы. Световой поток -- это тоже сигнал.
А как же информация хранится? Для того чтобы информацию сохранить, ее надо закодировать. Любая информация всегда хранится в виде кодов. Когда мы что-то пишем в тетради, мы на самом деле кодируем информацию с помощью специальных символов. Эти символы всем знакомы -- они называются буквами. И система такого кодирования тоже хорошо известна -- это обыкновенная азбука. Жители других стран те же самые слова запишут по-другому (другими буквами) -- у них своя азбука. Можно сказать, что у них другая система кодирования. В некоторых странах вместо букв используют иероглифы -- это еще более сложный способ кодирования информации.
Хранить можно не только текстовую и звуковую информацию. В виде кодов хранятся и изображения. Если посмотреть на рисунок с помощью увеличительного стекла, то видно, что он состоит из точек -- это так называемый растр. Координаты каждой точки можно запомнить в виде чисел. Цвет каждой точки тоже можно запомнить в виде числа. Эти числа могут храниться в памяти компьютера и передаваться на любые расстояния. По ним компьютерные программы способны изобразить рисунок на экране или напечатать его на принтере. Изображение можно сделать больше или меньше, темнее или светлее, его можно повернуть, наклонить, растянуть. Мы говорим о том, что на компьютере обрабатывается изображение, но на самом деле компьютерные программы изменяют числа, которыми отдельные точки изображения представлены в памяти компьютера.
2.2 Кодирование и декодирование
Рассмотрим некоторые примеры кодов [3, c. 29].
1. Азбука Морзе в русском варианте (алфавиту, составленному из алфавита русских заглавных букв и алфавита арабских цифр ставится в соответствие алфавит Морзе):
2. Код Трисиме (знакам латинского алфавита ставятся в соответствие комбинации из трех знаков: 1,2,3):
Читайте также: