
Базы данных ключ значение доклад
Обновлено: 02.07.2024
Базы данных NoSQL предлагают некоторые функции, которые отсутствуют в традиционных реляционных системах управления базами данных; например, они позволяют хранить простые пары ключ-значение для кэширования в течение короткого периода времени, сохранять неструктурированные коллекции данных, с которыми нельзя работать с помощью языка структурированных запросов SQL, и т.п.
В данной статье речь пойдёт о популярных СУБД NoSQL, их функциях и целях.
Системы управления базами данных
Базы данных – это логически организованные хранилища для различных видов данных. Каждая БД имеет свою модель, которая определяет структуру данных. Системы управления базами данных – это приложения (или библиотеки), которые управляют различными базами данных.
Примечание: Чтобы узнать больше о системах управления базами данных, читайте эту статью.
Системы управления базами данных NoSQL
В прошлом десятилетии лучшим средством для хранения данных считались реляционные СУБД. Такие СУБД не очень гибкие, но позволяют создавать производительные и сложные базы данных. Раньше этого было более чем достаточно, однако сегодня у разработчиков возникают другие потребности.
По своей конструкции базы данных NoSQL не основаны ни на одной модели (в отличие от РСУБД, которые основаны на реляционной модели). Каждая база данных, в зависимости от целей и функциональности, использует свою модель.
Существует несколько различных операционных моделей и систем для баз данных NoSQL:
Рассмотрим эти модели подробнее
Такие СУБД можно считать самой базовой реализацией NoSQL.
Они работают путём сопоставления ключей со значениями (как в словаре), между которыми нет ни структуры, ни отношений. Подключившись к серверу базы данных, (например, Redis), приложение может определить ключ (например, the_answer_to_life) и установить его значение (например, 42)ю позже эту пару можно извлечь посредством ключа.
Хранилища колонок
Документо-ориентированные базы данных
Документо-ориентированные базы данных NoSQL пользуются огромной популярностью среди пользователей. Эти СУБД похожи на хранилища колонок, однако позволяют создать более сложную структуру (документ в документе в документе…).
Документы устраняют некоторые ограничения хранилищ колонок. В целом они позволяют создать документ из произвольной структуры данных любой сложности.
Несмотря на высокую производительность и множество преимуществ, документо-ориентированные СУБД имеют некоторые недостатки и уязвимости по сравнению с другими СУБД NoSQL . Например, извлекая значение записи, вы получаете огромный объём данных, а обновление данных негативно влияет на производительность.
Графовые СУБД
Графовые базы данных представляют данные совсем иначе, чем предыдущие три модели. Они используют древовидные структуры – графы, которые состоят из узлов и рёбер.
Графовые СУБД соединяют и группируют полученные данные, благодаря чему они намного быстрее справляются с некоторыми операциями.
Эти базы данных обычно используются приложениями, которым необходимы четкие границы для подключений. К примеру, при регистрации в любой социальной сети ваш аккаунт связывается с аккаунтами ваших друзей, друзей ваших друзей и т.д. Такую операцию проще всего выполнить при помощи графовой БД.
В этой статье мы познакомимся с разными типами NoSQL СУБД.
Всего есть 4 основных типа:
Такие базы данных как правило используют хеш-таблицу, в которой находится уникальный ключ и указатель на конкретный объект данных. Существует понятие блока (bucket) — логической группы ключей, которые не группируют данные физически. В разных блоках могут быть идентичные ключи.
Производительность сильно вырастает за счёт кеширующих механизмов, которые работают на основе маппингов. Чтобы прочитать значение, вам нужно знать как ключ, так и блок, поскольку на самом деле ключ является хешем (блок + ключ).
Если поразмыслить о теореме CAP, то становится довольно очевидно, что такие хранилища хороши в плане доступности (Availability) и устойчивости к разделению (Partition tolerance), но явно проигрывают в согласованности данных (Consistency).
Пример: посмотрим на набор данных, представленных таблицей ниже. Здесь ключ — это название страны, а значение — список адресов в этой стране:

База данных такого типа позволяет читать и записывать значения с помощью ключа следующим образом:
- Get(key) возвращает значение, связанное с переданным ключом;
- Put(key, value) связывает значение с ключом;
- Multi-get(key1, key2, . keyN) возвращает список значений, связанных с переданным ключами;
- Delete(key) удаляет запись для ключа из хранилища.
Второй недостаток в том, что при увеличении объёмов данных, поддержание уникальных ключей может стать проблемой. Для её решения необходимо как-то усложнять процесс генерации строк, чтобы они оставались уникальными среди очень большого набора ключей.
Riak и Dynamo от Amazon — самые популярные СУБД данных такого типа.
Документоориентированная база данных
Тот факт, что такие базы данных работают без схемы, делает простой задачей добавление полей в JSON-документы без необходимости сначала заявлять об изменениях.
Couchbase и MongoDB — самые популярные документоориентированные СУБД.
Колоночная база данных
В колоночных NoSQL базах данных данные хранятся в ячейках, сгруппированных в колонки, а не в строки данных. Колонки логически группируются в колоночные семейства. Колоночные семейства могут состоять из практически неограниченного количества колонок, которые могут создаваться во время работы программы или во время определения схемы. Чтение и запись происходит с использованием колонок, а не строк.
В сравнении с хранением данных в строках, как в большинстве реляционных баз данных, преимущества хранения в колонках заключаются в быстром поиске/доступе и агрегации данных. Реляционные базы данных хранят каждую строку как непрерывную запись на диске. Разные строки хранятся в разных местах на диске, в то время как колоночные базы данных хранят все ячейки, относящиеся к колонке, как непрерывную запись, что делает операции поиска/доступа быстрее.
Пример: получение списка заголовков нескольких миллионов статей будет трудоёмкой задачей при использовании реляционных баз данных, так как для извлечения заголовков придётся проходить по каждой записи. А можно получить все заголовки с помощью только одной операции доступа к диску.
- Колоночное семейство — структура, которая может легко группировать колонки и суперколонки;
- Ключ — постоянное имя записи. У ключей может быть разное количество колонок, поэтому база данных может расширяться неравномерно;
- Пространство ключей — определяет самый внешний уровень организации, как правило, имя приложения/базы данных.
- Колонка — имеет упорядоченный список элементов — кортежей с именами и значениями.
Самыми известными примерами являются Google BigTable и HBase с Cassandra, вдохновлённые BigTable.
BigTable представляет собой высокопроизводительное, сжатое и проприетарное хранилище данных от Google. У него есть следующие атрибуты:
- Разреженность — некоторые ячейки могут быть пустыми;
- Распределённость — данные разделены между многими узлами;
- Постоянство — хранится на диске;
- Многомерность — более 1 измерения;
- Сопоставление — ключ и значение;
- Отсортированность — сопоставления обычно не сортируются, но этот случай — исключение.
Двумерная таблица, состоящая из строк и колонок, является частью реляционной системы баз данных.

Эту таблицу можно представить в виде BigTable-сопоставления следующим образом:
На колонки можно ссылаться с помощью колоночного семейства.
Графовая база данных
В графовой базе данных вы не найдёте строгого формата SQL или представления таблиц и колонок, вместо этого используется гибкое графическое представление, которое идеально подходит для решения проблем масштабируемости. Графовые структуры используются вместе с рёбрами, узлами и свойствами, что обеспечивает безиндексную смежность. При использовании графового хранилища данные могут быть легко преобразованы из одной модели в другую.
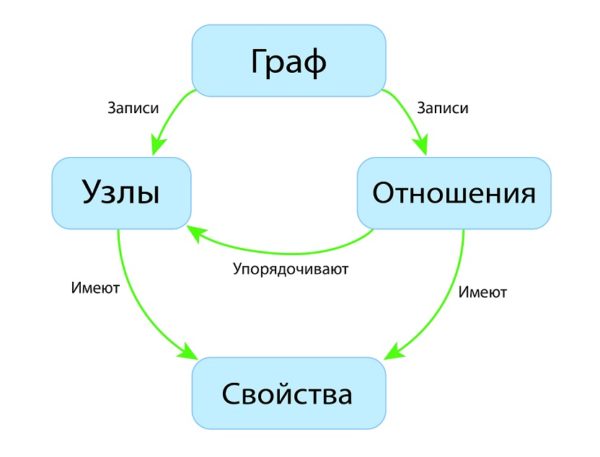
- Такие базы данных используют рёбра и узлы для представления данных.
- Узлы связаны между собой определённым отношениями, представленными рёбрами между ними.
- У узлов и отношений есть некоторые свойства.

Контейнерная иерархия документоориентированной базы данных содержит данные без схемы, которые можно представить в виде дерева, которое является графом. Если обращаться к документам или их элементам в этом дереве, можно получить более выразительное представление данных, в котором можно легко ориентироваться с помощью Neo4j.
Далее описаны некоторые особенности графовой базы данных на основе примера ниже:
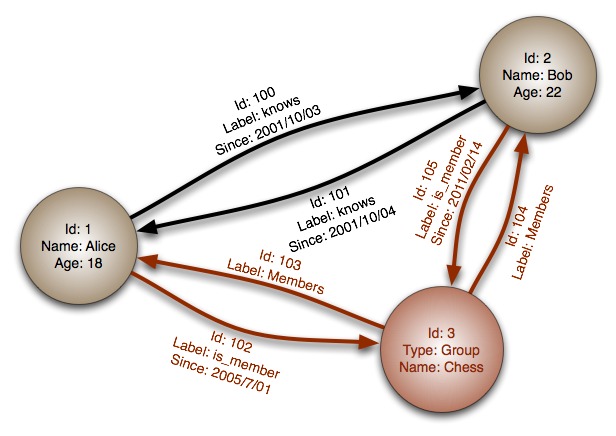
Хотя реляционные базы данных могут скопировать поведение графовых, рёбрам потребуется соединение (JOIN), что дорого обойдётся.
Пример использования
InfoGrid и Infinite Graph — самые популярные графовые базы данных. InfoGrid позволяет соединять множество рёбер (Relationships) и узлов (MeshObjects), что упрощает представление набора информации со сложными взаимными ссылками.

Автор Анна Вичугова
NoSQL – это подход к реализации масштабируемого хранилища (базы) информации с гибкой моделью данных, отличающийся от классических реляционных СУБД. В нереляционных базах проблемы масштабируемости (scalability) и доступности (availability), важные для Big Data, решаются за счёт атомарности (atomicity) и согласованности данных (consistency) [1].
Зачем нужны нереляционные базы данных в Big Data: история появления и развития

Какие бывают NoSQL-СУБД: основные типы нереляционных баз данных
Все NoSQL решения принято делить на 4 типа:
Чем хороши и плохи нереляционные базы данных: главные достоинства и недостатки
По сравнению с классическими SQL-базами, нереляционные СУБД обладают следующими преимуществами:
Обратной стороной вышеуказанных достоинств являются следующие недостатки:
- ограниченная емкость встроенного языка запросов [5]. Например, HBase предоставляет всего 4 функции работы с данными (Put, Get, Scan, Delete), в Cassandra отсутствуют операции Insert и Join, несмотря на наличие SQL-подобного языка запросов. Для решения этой проблемы используются сторонние средства трансляции классических SQL-выражений в исполнительный код для конкретной нереляционной базы. Например, Apache Phoenix для HBase или универсальный Drill.
- сложности в поддержке всехACID-требований к транзакциям (атомарность, консистентность, изоляция, долговечность) из-за того, что NoSQL-СУБД вместо CAP-модели (согласованность, доступность, устойчивость к разделению) скорее соответствуют модели BASE (базовая доступность, гибкое состояние и итоговая согласованность) [1]. Впрочем, некоторые нереляционные СУБД пытаются обойти это ограничение с помощью настраиваемых уровней согласованности, о чем мы рассказывали на примере Cassandra. Аналогичным образом Riak позволяет настраивать требуемые характеристики доступности-согласованности даже для отдельных запросов за счет задания количества узлов, необходимых для подтверждения успешного завершения транзакции [1]. Подробнее о CAP-и BASE-моделях мы расскажем в отдельной статье.
- сильная привязка приложения к конкретной СУБД из-за специфики внутреннего языка запросов и гибкой модели данных, ориентированной на конкретный случай [5];
- недостаток специалистов поNoSQL-базам по сравнению с реляционными аналогами [5].
Любые данные где-то хранятся. Будь это интернет вещей или пароли в *nix. Показываем схемы основных типов баз данных, чтобы наглядно представить различия между ними.

Типы баз данных, называемых также моделями БД или семействами БД, представляют собой шаблоны и структуры, используемые для организации данных в системе управления базами данных (СУБД). Выбор типа повлияет на то, какие операции сможет выполнять приложение, как будут представлены данные, на функции СУБД для разработки и рантайма.
Начнём с трёх типов БД, которые всё ещё могут встречаться в специализированных средах, но в основном заменены надежными и производительными альтернативами.
1. Простые структуры данных
Первый и простейший способ хранения данных – текстовые файлы. Метод применяется и сегодня для работы с небольшими объёмами информации. Для разделения полей используется специальный символ: запятая или точка с запятой в csv-файлах датасетов, двоеточие или пробел в *nix-подобных системах:
/etc/passwd в *nix системе
- ограничен тип и уровень сложности хранимой информации;
- трудно установить связи между компонентами данных;
- отсутствие функций параллелизма;
- практичны только для систем с небольшими требованиями к чтению и записи;
- используются для хранения конфигурационных данных;
- нет необходимости в стороннем программном обеспечении.
- /etc/passwd и /etc/fstab в *nix-системах
- csv-файлы
2. Иерархические базы данных

Пример построения иерархических связей
3. Сетевые базы данных
Сетевые базы данных расширяют функциональность иерархических: записи могут иметь более одного родителя. А значит, можно моделировать сложные отношения.

Пример связей в сетевой базе данных
- сетевые базы данных представляются не деревом, а общим графом
- ограничены теми же шаблонами доступа, что иерархические БД
4. SQL базы данных
Реляционные базы данных – старейший тип до сих пор широко используемых БД общего назначения. Данные и связи между данными организованы с помощью таблиц. Каждый столбец в таблице имеет имя и тип. Каждая строка представляет отдельную запись или элемент данных в таблице, который содержит значения для каждого из столбцов.

- поле в таблице, называемое внешним ключом, может содержать ссылки на столбцы в других таблицах, что позволяет их соединять;
- высокоорганизованная структура и гибкость делает реляционные БД мощными и адаптируемыми ко различным типам данных;
- для доступа к данным используется язык структурированных запросов (SQL);
- надёжный выбор для многих приложений.

- хранилища обеспечивают быстрый и малозатратный доступ;
- часто хранят данные конфигураций и информацию о состоянии данных, представленных словарями или хэшем;
- нет жёсткой схемы отношения между данными, поэтому в таких БД часто хранят одновременно различные типы данных;
- разработчик отвечает за определение схемы именования ключей и за то, чтобы значение имело соответствующий тип/формат.
6. Документная база данных

- база данных не предписывает опредёленный формат или схему;
- каждый документ может иметь свою внутреннюю структуру;
- документные БД являются хорошим выбором для быстрой разработки;
- в любой момент можно менять свойства данных, не изменяя структуру или сами данные.
7. Графовая база данных
Вместо сопоставления связей с таблицами и внешними ключами, графовые базы данных устанавливают связи, используя узлы, рёбра и свойства.

Графовые базы представляют данные в виде отдельных узлов, которые могут иметь любое количество связанных с ними свойств.
- выглядят аналогично сетевым;
- фокусируются на связях между элементами;
- явно отображает связи между типами данных;
- не требуют пошагового обхода для перемещения между элементами;
- нет ограничений в типах представляемых связей.
8. Колоночные базы данных
Колоночные базы данных (также нереляционные колоночные хранилища или базы данных с широкими столбцами) принадлежат к семейству NoSQL БД, но внешне похож на реляционные БД. Как и реляционные, колоночные БД хранят данные, используя строки и столбцы, но с иной связью между элементами.

- БД удобны при работе с приложениями, требующими высокой производительности;
- данные и метаданные записи доступны по одному идентификатору;
- гарантировано размещение всех данных из строки в одном кластере, что упрощает сегментацию и масштабирование данных.
9. Базы данных временных рядов
Базы данных временны́х рядов созданы для сбора и управления элементами, меняющимися с течением времени. Большинство таких БД организованы в структуры, которые записывают значения для одного элемента. Например, можно создать таблицу для отслеживания температуры процессора. Внутри каждое значение будет состоять из временной метки и показателя температуры. В таблице может быть несколько метрик.

- ориентированы на запись;
- предназначены для обработки постоянного потока входных данных;
- производительность зависит от количества отслеживаемых элементов, интервала опроса между записью новых значений и фактической полезной нагрузки данных.
NewSQL и многомодельные БД являются разными типами баз данных, но решают одну группу проблем, вызванных полярными подходами SQL или NoSQL-стратегии. Почему бы не объединить преимущества обеих групп?
10. NewSQL базы данных
NewSQL базы данных наследуют реляционную структуру и семантику, но построены с использованием более современных, масштабируемых конструкций. Цель – обеспечить большую масштабируемость, нежели реляционные БД, и более высокие гарантии согласованности, чем в NoSQL. Компромисс между согласованностью и доступностью является фундаментальной проблемой распределённых баз данных, описываемой теоремой CAP.
- возможность горизонтального масштабирования;
- высокая доступность;
- большая производительность и репликация;
- небольшой функционал и гибкость;
- немалое потребление ресурсов и необходимость специализированных знаний для работы с базой данных.
11. Многомодельные базы данных
Многомодельные базы данных – базы, объединяющие функциональные возможности нескольких видов БД. Преимущества такого подхода очевидны – одна и та же система может использовать различные представления для разных типов данных.
Совместное размещение данных из нескольких типов БД в одной системе позволяет выполнять новые операции, которые в противном случае были бы затруднены или невозможны. Например, многомодельные базы могут позволить юзерам получить доступ к данным, хранящимся в разных типах БД, и управлять ими в рамках одного запроса, а также поддерживают согласованность данных при выполнении операций, изменяющих информацию сразу в нескольких системах.
- помогают уменьшить нагрузку на СУБД;
- позволяют расширяться до новых моделей по мере изменения потребностей без внесения изменений в базовую инфраструктуру;
- обеспечивают непрерывный доступ и простое распределение данных;
- имеют линейную масштабируемость и просты для разработки.
Заключение
Изменение типов хранимых данных, требования к скорости и производительности привели и к продолжающемуся расширению типов баз данных. При этом каждый из них продолжает быть нужным в своей нише, где взаимосвязи между данными ассоциируются с определенной схемой строения базы данных.
Читайте также: